

In this blog, let us know what Amazon Redshift is all about and also dive into its working mechanism in handling data efficiently, unlike traditional databases. Come on, let’s dive deep into the Amazon Redshift which plays a significant role in AWS Certified Data Engineer Associate Certification (DEA-C01).
Introduction to Amazon Redshift
Amazon Redshift is a data warehousing service designed for storing petabytes of data used for reporting and analytics. Unlike the traditional databases and data lakes excel at storing data, to turn raw data into insights, you need a data warehouse. Stored data doesn’t reveal anything; you need to analyze that data to make informed choices. Cloud data warehouses act as a centralized repository for historical data and create a unified platform for analysis and decision-making.
Redshift is a fully managed AWS Service and is designed for Online Analytical Processing (OLAP) workloads. It’s perfect for analyzing large amounts of historical data using standard SQL and business intelligence tools. It can ingest structured and semi-structured data in multiple data formats. This uses SQL to analyze this data across data warehouses, operational databases, and data lakes.
Amazon Redshift for Data Warehousing
Here are a few reasons for you to choose Amazon Redshift for warehousing.
- Enterprise scale big data analysis.
- Supporting different file formats like CSV, TSV, Parquet, ORC, JSON, Avro, etc.
- Seamlessly integrates with AWS services, making infrastructure management simple.
- Supports data lakes and allows loading and unloading of data with simple steps
- Improves performance and lowers cost through scaling features such as elastic resize and concurrency.
- It is suitable for different use cases, such as business intelligence and analytics, real-time data processing, and machine learning
Amazon Redshift Architecture and Components
Most components of Redshift’s architecture include clusters, leader nodes, compute nodes, and client applications.
A Redshift modern data architecture allows you to:
- Query data in your data lake is easy to write back to your data lake in open formats.
- Merging and processing data from different sources using common SQL statements
- Using familiar SQL statements, it combines and processes all your data in stores.
- Run queries on live data without the need for any data loading and ETL Process Pipelines.

-
Amazon Redshift Clusters and Nodes
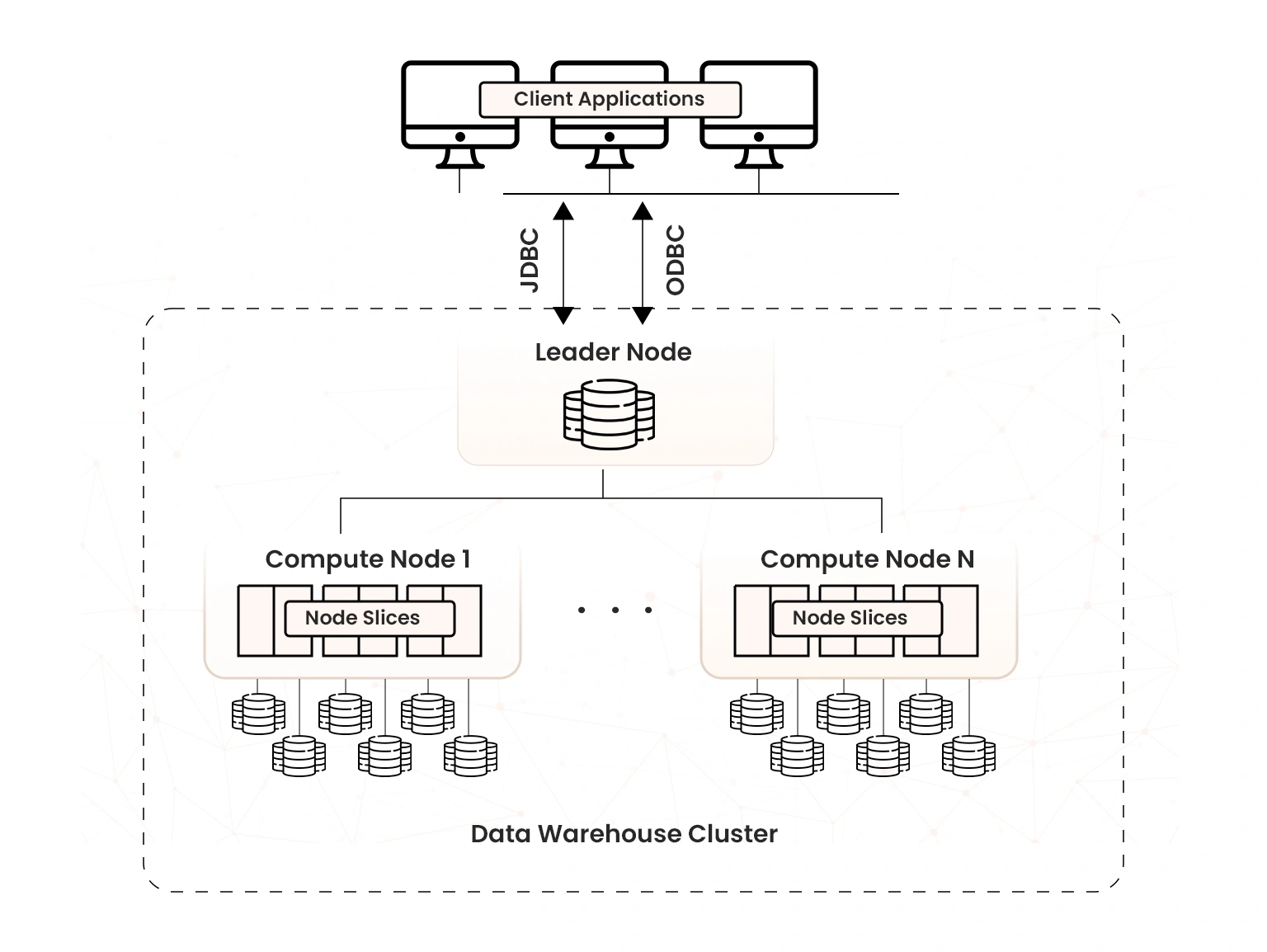
RedShift is a cluster-based solution. A cluster is a set of computing resources called nodes with one leader node and one or more EC2 compute nodes. The number of compute nodes needed depends on the size of the data, the number of queries run, and the required query executive performance. A Redshift cluster is a single availability zone concept.
Leader node: It receives queries from client applications, parses the queries, and develops execution plans, which are an ordered set of steps to process these queries. The leader node then coordinates the parallel execution of these plans with the computer nodes, aggregates the intermediate results from these nodes, and finally returns the results back to the client applications. You can have only one leader node.
The leader node facilitates communication from the SQL client and BI tools to the compute nodes.
- Acts as the SQL endpoint
- Stores metadata of the entire cluster
- Coordinates parallel processing
Compute nodes: They run the steps specified on the execution plans and transmit data among themselves to serve these queries. The intermediary results send back the leader node to aggregate before being sent to the client applications.
- Have dedicated compute resources
- Run queries in parallel
- Scale out and in; up and down
- Load, unload, back up, and restore data
-
Columnar Storage and MPP Architecture
The main features that drive Redshift’s performance are columnar storage, Massive Parallel Processing (MPP), and compute nodes. Together, these three features allow Redshift to handle complex queries on large datasets.
Redshift is based on a columnar database. This database management system stores data tables as columns rather than as rows. A column-oriented database allows you to skip non-relevant data. It helps avoid wasted reads and enhances query performance and data retrieval.
MPP distributes queries across compute nodes for parallel processing. Each compute node is divided into slices, and each slice gets a portion of CPU, memory, and storage. Slices act as virtual compute nodes. Queries are broken into smaller tasks and run across slices to improve performance. In an MPP environment, Redshift uses different distribution styles to access data in columnar storage. While loading data to Redshift, split large files into smaller files to take advantage of MPP.
-
Amazon Redshift Spectrum for Querying S3 Data
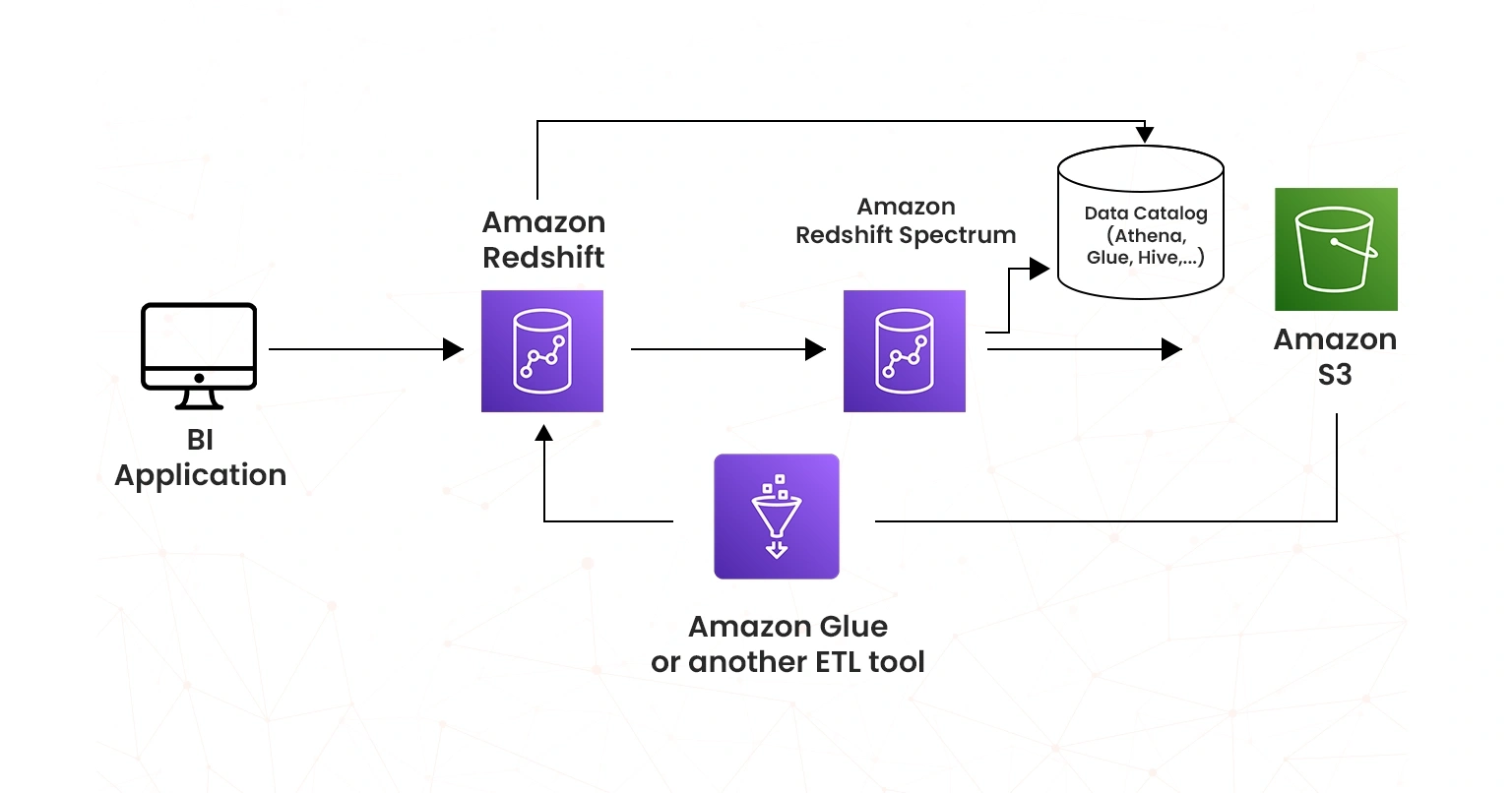
Amazon Redshift Spectrum is a Redshift feature for querying and retrieving data from Amazon S3. It allows you to analyze large volumes of data without having to wait for ETL jobs to get access to your data. You can query exabytes of data in S3 without having to load the data in Redshift. Spectrum runs on a dedicated server, outside the Redshift cluster, and it scales automatically to process queries efficiently, depending on the volume of data being queried from S3.
Redshift Spectrum stores and allows querying of data in Amazon S3 using a concept called external tables, which are defined in an external data catalog. Redshift can refer to tables from Redshift Spectrum and can refer to data catalogs from Amazon Glue, Athena, or EMR.
What are the Key Features of Amazon Redshift?
Here are the key features that distinguish Redshift from other data warehouse solutions.
- Massively Parallel Processing: Able to run complex queries in parallel
- Shared nothing architecture: Compute nodes with independent compute resources ensure no two nodes share the same data
- Automated Data Management: Automatic data backup, replication, and scaling without downtime
- Designed for OLAP: Suitable for Online Analytical Processing (OLAP), analytics, and reporting


Scalability and Performance Optimization
Redshift comes with various features for scalability and performance improvement:
- Concurrency scaling: This feature automatically adds more compute power temporarily to meet the demand of high concurrency. When you enable this feature, eligible queries are sent to the concurrency-scaling cluster instead of waiting in a queue, thereby improving query performance.
- Elastic resize: While resizing the cluster, they are updated by adding or reducing an existing cluster or changing the node type for a cluster. This flexibility allows you to scale up and scale down to meet demand and cost.
- Redshift Spectrum with S3: Access S3 data directly by using RedShift Spectrum, with faster query time.
Amazon Redshift Security and Compliance
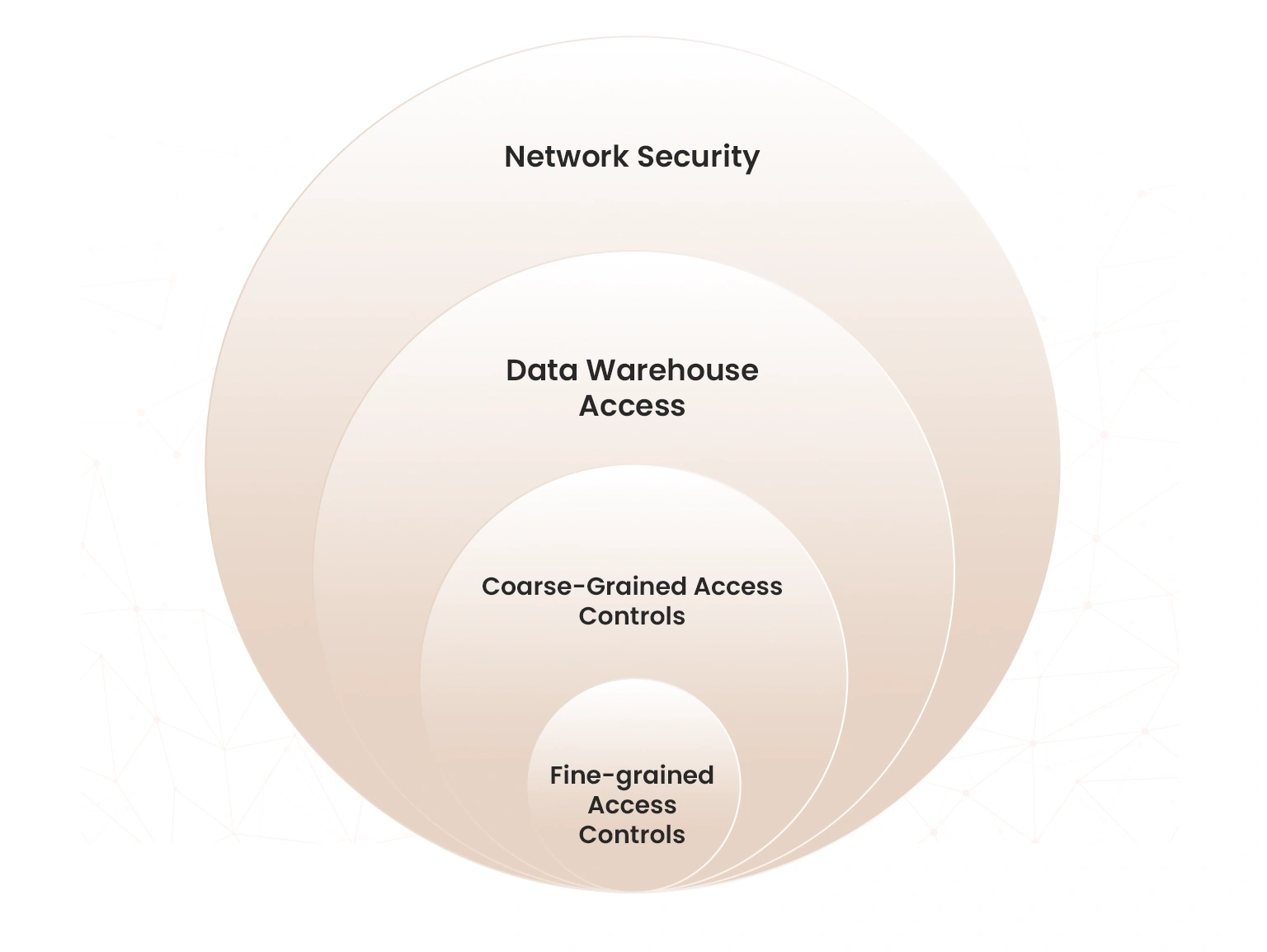
Redshift offers several security tiers to safeguard data and provide compliance with regulatory standards. It integrates with AWS for single sign-on, multi-factor authentication and granular access controls. Further, RedShift is assessed under various AWS compliance programs to ensure security and compliance with industry standards and regulations. Redshift combines data from different sources and provides insights that comply with SOC, PCI, FedRAMP, HIPAA, and others.
Amazon Redshift Workload Management (WLM)
The Workload Management (WLM) feature prioritizes queries by categorizing them into distinct queues to optimize performance and resource utilization. WLM prevents long queries from holding up short, fast-running queries or prevents ad hoc exploratory queries from holding up high-critical queries. WLM is set up through parameter groups. Redshift uses these parameters to control the behavior and performance of your databases. You can have up to 8 queries. WLM has two modes: automatic (comes with the default parameter group) and manual (requires a customer parameter group).
Conclusion
To sum up, this fully managed cloud solution built on Postgres and Amazon Redshift is easy to use and can integrate with other tools and services seamlessly. Its flexibility makes it ideal for different use cases, as you can scale it depending on your requirements. The pay-as-you-go and pay-per-query (for Redshift Spectrum) pricing models allow you to scale up effectively while keeping control over your spending. Connect now to know how you can effectively learn Redshift with our AWS-certified data engineer certification exam, with a focus on hands-on learning using Sandboxes and Hands-on labs.
- What Is Amazon Redshift and How Does It Work? - April 28, 2025
- What Is the Role of AWS Lambda in AI Model Deployment? - April 2, 2025
- What Are ETL Best Practices for AWS Data Engineers - March 17, 2025
- How to Create Secure User Authentication with AWS Cognito for Cloud Applications - September 30, 2024
- 2024 Roadmap to AWS Security Specialty Certification Success - August 16, 2024
- Top 25 AWS Full Stack Developer Interview Questions & Answers - August 14, 2024
- AWS Machine Learning Specialty vs Google ML Engineer – Difference - August 9, 2024
- Deploy a serverless architecture using AWS Lambda and Amazon API Gateway - August 9, 2024
