
Machine learning is one of the formidable technological advancements in recent years. The popularity of machine learning obtains major support for change in the focus of organizations on data-driven decisions. Therefore, you can find a prominent demand for professionals skilled in machine learning. As a result, you can also find candidates looking for machine learning interview questions with a simple Google Search!
Since the technological perspective of machine learning is evolving gradually, the interview process also involves certain changes. A few years back, knowledge about designing a convolutional network could have granted you access to promising jobs in machine learning. However, times have changed. Machine learning now places wider expectations in algorithms, probability, statistics, data structure, and many more. Therefore, candidates need comprehensive preparation with machine learning tools and top machine learning interview questions.
As we all know, machine learning and data science are closely related disciplines. Machine learning engineer is one of the top job roles in machine learning and data science. So, our attention on top machine learning interview questions is not futile. In 2019, machine learning engineers can earn $146,085 on an average per year with a splendid annual growth rate of 344 percent. Therefore, rapid growth in salary and opportunities for promising job roles implies the need for better preparation for machine learning interviews.
Also Read: An Introduction to Amazon Machine Learning
Top Machine Learning Interview Questions and Answers
We’ve discussed the importance of machine learning interview for your IT career till now. So, do you want to succeed in your first attempt at a machine learning interview? If yes, you have arrived at the right place! This discussion would present some of the best machine learning interview questions. The primary objective of this discussion is to present a reliable tool for your machine learning interview preparations.
Generally, you would assume that the questions for freshers would be very easy, and basic ML knowledge will help. That’s true! Interviewers would ask machine learning interview questions for experienced candidates as follow-up questions. Why? As you prove your basic knowledge of machine learning, the interviewers can try to dig deeper into your capabilities. So, an all-round preparation of the latest machine learning interview questions can help you succeed in an interview.
The following discussion would present questions for machine learning interviews in five different categories. Each category of machine learning interview questions would contain 10 entries that can help in understanding the type of questions. If you are excited to land up a job in machine learning, then why wait? Let’s start!
Alexa skill builder is one of the most common options for a Machine Learning career in AWS. You can learn more about this by learning more about the AWS Skill Builder Specialty certification.
Machine Learning Interview Questions for Data Engineers
The first category under the most popular interview questions is the machine learning interview questions for data engineers. As the knowledge of machine learning can help data engineers to bring their career to the next level, it is worth to cover these questions here. So, let’s go through the best machine learning interview questions for data engineers.
1. What is Bias error in ML algorithms?
Answer: Candidates with experience in data engineering can find this entry in the latest machine learning interview questions. Bias is the general error in ML algorithms primarily because of simplistic assumptions. As the name implies, Bias error involves negligence for certain data points, thereby resulting in lower accuracy. Bias error is responsible for complicating the process of generalizing knowledge from the training set to test sets.
2. What is the meaning of Variance Error in ML algorithms?
Answer: Variance error is found in machine learning algorithms that are highly complex and pose difficulties in understanding them. As a result, you can find greater extent of variation in the training data. Subsequently, the machine learning model would overfit the data. In addition, you can also find excessive noise for training data which is completely inappropriate for the test data.
3. Can you define bias-variance trade-off?
Answer: Bias-variance trade-off is definitely one of the top machine learning interview questions for data engineers. Bias-variance trade-off is the instrument for managing learning errors as well as noise caused by underlying data. The trade-off between bias error and variance error can increase the complexity of the model. However, you can also observe a considerable reduction of errors with the bias-variance trade-off.
4. How can you differentiate supervised from unsupervised machine learning?
Answer: Supervised learning implies the requirement of data in the labeled form. An instance of supervised learning is labeling data and classifying it when you have to categorize the data. However, unsupervised learning does not require any form of explicit data labeling. This simple point can separate supervised learning from unsupervised learning quite easily. Candidates could easily expect this question among the latest machine learning interview questions.

5. What is the difference between a k-nearest algorithm and k-means clustering?
Answer: This is one of the frequently asked machine learning interview questions for data engineers. K-nearest algorithm comes under the scope of supervised learning, and the k-means clustering comes under the scope of unsupervised learning. The two techniques appear similar in terms of appearance, albeit with prominent differences. The most notable difference between these two technologies relates to supervised and unsupervised learning.
K-nearest algorithm implies supervised learning, thereby suggesting the need for labeling data explicitly. On the other hand, K-means clustering does not require any form of data labeling. Therefore, you can implement any technology based on the needs of a project.
6. What is the ROC curve, and how does it work?
Answer: Receiver Operating Characteristic (ROC) curve provides a pictorial representation of the contrast level between false-positive rates and true positive rates. The estimates of true and false positive rates are taken at multiple thresholds. The ROC is ideal as a proxy for measuring trade-offs and sensitivity associated to a model. According to the measurements of sensitivity and trade-off, the curve can trigger the false alarms.
7. What is the importance of Bayes’ theorem in ML algorithms?
Answer: Candidates should have adequate preparation for such frequently asked machine learning interview questions in data engineer interviews. Bayes’ theorem can help in measuring the posterior probability of an event according to previous knowledge. Bayes’ theorem can inform about the true positive rate of conditions after division by the sum total of false rates. The formula for Bayes’ theorem is,
P (A|B) = [P(B|A) P(A)] / [P(B)]
Bayes Theorem is an ideal instrument in mathematics for calculation of conditional probability. A renowned mathematician named Thomas Bayes was the creator of this theorem. Many people can find Bayes theorem confusing. However, it also helps for in-depth understanding and gaining productive insights regarding a topic.
8. What is precision, and what is a recall?
Answer: The recall is the number of true positive rates identified for a specific total number of datasets. Precision involves predictions for positive values claimed by a model as compared to the number of actually claimed positives. You can assume this as a special case for probability with respect to mathematics.
9. Can you explain the difference between L1 and L2 regularization?
Answer: Candidates can face this question in their interview as it’s one of the latest machine learning interview questions. L2 regularization is more likely to transfer error across all terms. On the other hand, L1 regularization is highly sparse or binary. Many variables in L1 regularization involve the assignment of 1 or 0 in weighting to them. The case of L1 regularization involves the setup of Laplacian prior to the terms. In the case of L2, the focus is on the setup of Gaussian prior on the terms.
10. What is Naive Bayes?
Answer: Naive Bayes is ideal for practical application in text mining. However, it also involves an assumption that it is not possible to visualize in real-time data. Naive Bayes involves the calculation of conditional probability from the pure product of individual probabilities of different components. The condition in such cases would imply complete independence for the features that are practically not possible or very difficult. Candidates should expect this type of follow-up machine learning interview questions.
Machine Learning as an application of Artificial Intelligence has brought so many benefits for businesses with Big Data. Check out what’s the Role of Big Data and AI in the Business World.
Machine Learning Interview Questions for Data Scientists
The next category involves the most common machine learning interview questions for data scientists. Just like data engineers, the role of data scientists is based on their skills related to big data analysis with machine learning. So, let’s go through the frequently asked Machine Learning interview questions for data scientists.
11. What is the F1 score, and how can you use it?
Answer: You can define the F1 score as the measurement of performance of a machine learning model. The F1 score is the weighted average of precision and recall of a specific machine learning model. The results can vary from a scale of 0 to 1 with 1 as an indicator of best performance. The applications of F1 score are ideal for classification tests which do not focus on true negatives very much.
12. Is it possible to manage an imbalanced dataset? If yes, how?
Answer: This is probably one of the toughest machine learning interview questions in data scientist interviews. The imbalanced dataset is found in cases of classification test and allocation of 90% of data in one class. As a result, you can encounter problems. Without any predictive power over the other data categories, the accuracy of around 90% could skew. However, it is possible to manage an imbalanced dataset.
You can try collecting more data to compensate for the imbalances in the dataset. You could also try re-sampling of the dataset in order to correct imbalances. Most important of all, you could try another completely different algorithm on the dataset. The important factor here is the understanding of the negative impacts of an imbalanced dataset and approaches for balancing the irregularities.
13. How is Type I error different from Type II error?
Answer: Don’t panic when you find such a basic question in an interview for data scientists. The interviewers might be testing your knowledge of basic ML concepts and ensuring that you are at the top of your game. Type I error classified as false positive, and Type II error classifies as a false negative. It means that claiming about something happening when it actually hasn’t, classifies as Type I error.
On the other hand, Type II error is completely opposite. Type II error happens when you claim something is not happening when it actually is happening. Basically, Type I error is like informing a man that he is pregnant. On the other hand, Type II error is like telling a pregnant woman that she doesn’t carry a baby.
14. Do you know about Fourier transform?
Answer: Candidates can also find the latest machine learning interview questions on Fourier transform in their data scientist interview. The Fourier transform is a common tool for breaking down generic functions into a superposition of symmetric functions. Simply put, it’s like figuring out the recipe from a dish served to us.
Fourier transform helps in finding out the set of cycle speeds, phases, and amplitudes for matching any particular time signal. Fourier transform helps in the conversion of the signal from the time domain to the frequency domain. As a result, it becomes easier to extract features from audio signals and even other time series like sensor data.
15. What is the difference between deep learning and machine learning?
Answer: This is one of the common machine learning interview questions that you can find in almost every list. Deep learning develops as a subset of machine learning and involves prominent relation with neural networks. Deep learning involves the use of backpropagation and specific principles of neuroscience.
The applications of deep learning help in the accurate modeling of massive sets of semi-structured or unlabeled data. Deep learning provides a representation of the unsupervised learning algorithm. In contrast to other machine learning algorithms, deep learning uses neural networks for learning data representations.
16. How is the generative model different from the discriminative model?
Answer: The generative model will review the data categories. However, a discriminative model would review the difference between various data categories. Generally, discriminative models have better performance than generative models in classification tasks.
17. Is model accuracy important or model performance?
Answer: This question is ideal for testing the fluency of an individual regarding machine learning model performance. Models with higher accuracy could not perform well in terms of predictive power. How does this happen? Generally, the model accuracy is a subset of model performance, and it can also be misleading at certain times. If you have to detect fraud in large datasets with a sample of millions, the more accurate model would not predict any fraud.
This condition is possible if only a large minority of cases, involving fraud. As for a predictive model, this condition would be inappropriate. Imagine that a model designed for fraud shows that there is no sign of fraud! Therefore, we can clearly ascertain that model accuracy is not the sole determinant of model performance. Both elements are highly significant in machine learning.
18. In which situation is classification better than regression?
Answer: Classification results in the generation of discrete values and dataset according to specific categories. On the other hand, regression provides continuous results with better demarcations between individual points. Classification is better than regression when you need the results to reflect the presence of data points in explicit categories in the dataset. Classification is better if you just want to find whether a name is female or male. Regression is ideal if you want to find out the correlation of the name with male and female names.
19. Can you provide an example of using ensemble techniques?
Answer: Ensemble technique involves a combination of learning algorithms for optimization of improved predictive performance. Ensemble techniques help in reducing overfitting issues in models. As a result, the model becomes more robust and faces fewer chances of influence from trivial changes in training data.
20. Explain about your favorite algorithm in less than a minute.
Answer: You can also come across such machine learning interview questions based on your experience. In the case of such questions, you need to develop skills for explaining the complex and technical aspect of algorithms. Most important of all, you have to maintain your poise and present your summary briefly and quickly. Ensure that you give explanations for other algorithms to the interviewer for a better advantage. In addition, you should also make sure that even a five-year-old could understand your explanation of machine learning algorithms.
Preparing to become an AWS Certified Machine Learning Specialist? Follow this comprehensive guide for AWS Machine Learning certification preparation and get ready for the exam.
Machine Learning Interview Questions for Freshers
The next category in the list is Machine Learning interview questions for freshers. The interviewer mainly asks some simple questions to the fresher candidate in order to check his basic knowledge and understanding of machine learning concepts. Not only freshers but the experienced candidates should also prepare themselves with these questions, so let’s move to the questions.
21. What is machine learning?
Answer: This is the most basic question that you can find generally at the start of every machine learning interview. Machine learning is a computer science discipline that relates to the use of system programming for automatic learning and improvement. The basic idea in machine learning is to predict suitable actions in specific scenarios based on experience. Robots function by performing tasks on the basis of data from their sensors.
22. How is data mining different from machine learning?
Answer: Machine learning involves study, design, and developing algorithms that can help computers to learn without explicit programming. On the other hand, data mining involves observation of patterns or extracting knowledge from unstructured data. Data mining uses machine learning algorithms for accomplishing this task.
23. What are the different types of machine learning?
Answer: This entry is one of the most commonly asked machine learning interview questions. Machine learning includes three different categories such as supervised, unsupervised, and reinforcement learning. Supervised learning involves the use of labeled data. Unsupervised learning involves training of model using unlabeled data or without proper guidance.
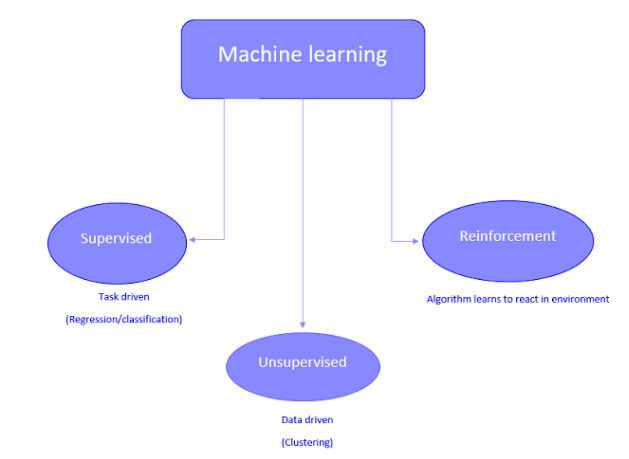
The model has to find patterns and relationships automatically from a dataset by creating clusters. Reinforcement learning depends on an agent for interaction with the environment through certain actions that help in recognizing rewards or errors. So, you can assume reinforcement learning as the ‘hit and trial’ method for machine learning.
24. Define overfitting in machine learning.
Answer: Overfitting happens in machine learning in scenarios where the statistical model does not describe the underlying relationship. On the contrary, the model describes random error and noise in overfitting. Overfitting is common in cases of highly complex models due to the excessive parameters than a number of training data types. Models with overfitting generally tend to show poor performance.
25. Name the five most popular machine learning algorithms.
Answer: The most popular machine learning algorithms are decision trees, probabilistic networks, and neural networks. The other two popular ML algorithms are support vector machines and neural networks or backpropagation networks.
26. What are the different approaches for machine learning?
Answer: This question is one of the most common machine learning interview questions for freshers. Candidates can present the response in the form of three distinct approaches. The first approach refers to the concept vs. classification learning. The second approach refers to inductive vs. analytical learning. The third approach for machine learning refers to symbolic vs. statistical learning.
27. Can you outline the functions of supervised and unsupervised learning?
Answer: Supervised learning performs functions such as classifications, speech recognition, regression, time series prediction, and string annotation. On the other hand, unsupervised learning performs functions such as identifying data clusters. In addition, unsupervised learning also helps in finding low-dimensional data representations. Unsupervised learning also helps in finding interesting directions in data as well as novel observations or database cleaning requirements. Unsupervised learning also identifies interesting coordinates and correlations.
28. Which areas can implement pattern recognition?
Answer: Candidates should find this entry among frequently asked machine learning interview questions for freshers. Pattern recognition is applicable in areas such as computer vision, data mining, and speech recognition. In addition, you can also find its applications in bioinformatics, statistics, and information retrieval.
29. What is dimension reduction in Machine learning?
Answer: Dimension reduction refers to the process of reducing random variables with considerations. As a result, the random variables find two groups, such as feature selection and feature extraction. Dimension reduction is an important concept in machine learning as well as statistics. Feature extraction techniques such as PCA, ICA, and KPCA are ideal for dimensionality reduction. PCA denotes Principal Components Analysis. ICA denotes Independent Component Analysis. KPCA stands for Kernel-based Principal Component Analysis.
30. Name some methods for Sequential Supervised Learning.
Answer: The different ideal methods for Sequential Supervised Learning include sliding-window methods and recurrent sliding windows. In addition, Hidden Markow models and Maximum entropy Markow models help in sequential supervised learning. The other two methods involve conditional random fields and graph transformer networks.
Try Now: Google Cloud Certified Professional Data Engineer Free Test
Machine Learning Interview Questions for Experienced
Now, we’ll get ahead with our next category – MachineL interview questions for experienced candidates. As you would have gained some considerable experience in machine learning. On the basis of the experience, candidates are asked some deeper and difficult questions. So, have a look and prepare yourself for these most common machine learning interview questions for experienced.
31. Explain the differences between a linked list and an array.
Answer: Candidates will generally find this mention among machine learning interview questions for experienced professionals. Linked list contains a series of objects with pointers for guidance on sequential processing. On the other hand, an array is simply an organized collection of objects. Every element in an array follows the assumption of the same size while a linked list does not have this trait.
Organic growth in a linked list is easier than an array which can require pre-definition or re-definition. Shuffling of a linked list involves lesser memory consumption due to pointers. On the other hand, reshuffling of an array can consume more memory.
32. What is a hash table?
Answer: Hash table is a data structure meant for production of a supporting array. The hash function helps in mapping a key to certain values. Hash table is ideal for different tasks such as database indexing.
33. How can you implement a recommendation system for a company’s users?
Answer: You can find different interview questions like this commonly for experienced machine learning candidates. You have to deal with these machine learning interview questions by referring to the use of machine learning models. The best response would be to identify the company’s problems through in-depth research on the company and industry.
Some of the important data points for the machine learning models to develop a recommendation system are important here. Revenue drivers of the company or the types of users in the company can provide the required data points.
34. How is gradient descent (GD) different from Stochastic gradient descent (SGD)?
Answer: Each algorithm helps in identifying a set of parameters for reducing a loss function. This happens through the evaluation of parameters against data followed by adjustments. In the case of standard gradient descent (GD), evaluation of all training samples in each set of parameters happens.
So, you will take big yet slower steps towards the solution. The stochastic gradient descent (SGD) involves evaluation of one training sample for a set of parameters before their updates. This seems similar to taking small yet quick steps towards the solution.
35. What is the use of Box-Cox transformation?
Answer: Box-Cox transformation is a type of power transformation that helps in the transformation of data for normalizing distribution. Box-Cox transformation is also ideal for stabilizing variance by eliminating heteroskedasticity.
36. Name three data preprocessing techniques for managing outliers.
Answer: Candidates can find this entry in machine learning interview questions for experienced candidates. The first technique involves Winsorize or cap at the threshold. The second technique involves Box-Cox transformation for reducing skew. The third technique involves removing outliers that are measurement errors or anomalies.
37. What is the right amount of data to allocate for training, validation, and test sets?
Answer: Candidates will get this entry from top machine learning interview questions for experienced professionals. The exact amount is not possible as we have to find the perfect balance. In the case of the too-small test set, we can have unreliable estimates for model performance.
In the case of the excessive small training set, actual model parameters can have high variance. The best-recommended practice, in this case, is the 80/20 or train/test split. Subsequently, you can split the train set into train/validation splits or partitions to ensure cross-validation.
38. How can you select a classifier on the basis of training set size?
Answer: In the case of a small training set, high bias and low variance models show better performance. The sole reason is that such models do not overfit easily. In the case of a large training set, low bias and high variant models show better performance. This is possible because of their capability to reflect more complex relationships.
39. What is Latent Dirichlet Allocation (LDA)?
Answer: LDA is one of the common topics in machine learning interview questions on unsupervised learning. LDA is a general method for topic modeling as well as classification of documents according to the subject matter. It is a generative model providing representation for documents as a combination of topics with its own probability distribution. LDA involves documents that are distributions of topics, that in the first place, are distributions of words.
40. How could you improve the efficiency of our marketing team?
Answer: You shall always depend on the type of company to answer such a question. The first recommendation could be the use of clustering algorithms for building custom customer segments. The second recommendation involves the prediction of conversion probability based on the user’s website behavior. The next recommendation could be natural language processing for headlines to predict performance.
Machine learning has revolutionized the world and cloud computing field is not untouched from it. If you are a data engineer on Google Cloud platform, get familiar with the Machine Learning on Google Cloud Platform.
Other Machine Learning Interview Questions
Finally, the discussion would present miscellaneous machine learning interview questions for the interview. Whether you are a fresher, experienced, data engineer or data scientist, you may come across these interview questions. So, don’t forget to check out
41. What is the difference between inductive and deductive learning?
Answer: Inductive learning involves using observations for reaching on conclusions. Deductive learning involves referring to conclusions for developing observations.
42. What is the difference between Information Gain and Entropy?
Answer: Entropy shows the level of disorganization in your data and reduces with increasing proximity to the leaf node. Information gain depends on a reduction in entropy following the spilling of a dataset on an attribute. Information gain increases with proximity to the leaf node.
43. What are the different categories in the sequence learning process?
Answer: The sequential learning process is one of the common topics in machine learning interview questions. The four categories include sequence prediction, sequent generation, sequence recognition, and sequential decision.
44. What are the different components in relational evaluation techniques?
Answer: The significant components of relational evaluation techniques include data acquisition, query type, significance test, and scoring metric. The other important components include a cross-validation technique and ground truth acquisition.
45. Name two paradigms in ensemble methods.
Answer: The two important paradigms of ensemble methods are parallel and sequential ensemble methods.

46. What are the components of Bayesian logic program?
Answer: The bayesian logic program involves two components. The first component is the logical component containing a set of Bayesian clauses. The second component is the quantitative component. The logical component deals with the qualitative aspect of the domain.
47. What are the pros and cons of neural networks?
Answer: You cannot miss this entry among common machine learning interview questions. Neural networks can provide performance breakthroughs for unstructured datasets like video, images, and audio. The higher flexibility in neural networks helps in learning patterns better than other ML algorithms. The cons of neural network imply towards the requirement of a large amount of training data. Furthermore, neural networks also have setbacks in terms of selecting architecture and understanding of underlying internal layers.
48. What are the pros and cons of decision trees?
Answer: Decision trees help in easy interpretation and a limited number of parameters for tuning. Decision trees are nonparametric, and hence they are not vulnerable to outliers. On the other hand, decision trees are highly vulnerable to overfitting. However, you can choose ensemble methods such as boosted trees or random forests to deal with such issues.
49. Can you explain about bagging?
Answer: Bagging is the short-form for bootstrap aggregating. Bagging is actually a meta-algorithm that takes M subsamples from the initial dataset as inputs. Subsequently, the algorithm trains a predictive model on the subsamples. The final model is a product of averaging bootstrapped models and provides better results.
50. What is a recommendation system?
Answer: A recommendation system is a subclass in the information filtering system for predicting preference that a user would assign to an item. The best techniques for recommendation system are collaborative filtering and content-based filtering.
Final Words
So, the above discussion is a clear reflection on different types of questions you can encounter in a machine learning interview. The primary focus of the discussion was on dividing questions based on their relevance. As a result, you can focus on particular categories of questions that suit your level of expertise. For example, if you are an experienced machine learning professional, you should go for machine learning interview questions for experienced along with other questions as a bonus.
Another benefit from the discussion is the illustration of practical questions that can involve multiples responses. The discussion outlined the best practice approach for responding to each question. However, you need to expand the scope of your preparation and research more to find out additional ML interview questions. If you are a Machine Learning engineer or data engineer on AWS platform, enroll now for the AWS Machine Learning Specialty practice tests and become a certified professional.
With the necessary bit of effort and dedication, a promising career is never far away!
- Top 45 Fresher Java Interview Questions - March 9, 2023
- 25 Free Practice Questions – GCP Certified Professional Cloud Architect - December 3, 2021
- 30 Free Questions – Google Cloud Certified Digital Leader Certification Exam - November 24, 2021
- 4 Types of Google Cloud Support Options for You - November 23, 2021
- APACHE STORM (2.2.0) – A Complete Guide - November 22, 2021
- Data Mining Vs Big Data – Find out the Best Differences - November 18, 2021
- Understanding MapReduce in Hadoop – Know how to get started - November 15, 2021
- What is Data Visualization? - October 22, 2021


What a great article! Thanks for sharing such useful information.
What a great effort! Thank you so much for sharing such outstanding content.
I was looking for answers about “Naive Bayes” questions and I found what I want here.
Excellent Blog! I would like to thank for the efforts you have made in writing this post. I am hoping the same best work from you in the future as well. Thanks for sharing. Great websites!
I Am really impressed about this blog because this blog is very easy to learn and understand clearly. This blog is very useful for the college students and researchers to take a good notes in good manner, I gained many unknown information.