

This blog presents how the AWS Certified Solutions Architect Professional (SAP-C02) exam tests your ability to design, develop, and implement fault-tolerant and reliable architecture. To become an AWS solution architect, you must understand the AWS reliability design principles, advanced concepts about designing distributed systems, and other best practices for creating resilient fault-tolerant systems.
Fault tolerance in SAP-C02 Exam Domain
Fault tolerance is the ability to withstand subsystem failure and maintain availability, without impacting AWS service-level agreement (SLA). The AWS Certified Solutions Architect – Professional (SAP-C02) exam covers fault tolerance extensively, almost in all domains. The exam checks advanced skills in designing optimized AWS solutions based on the six pillars of the AWS Well-Architected Framework. Fault tolerance is a key component of the Reliability Pillar.
Mastering fault-tolerant and high-availability design patterns and services, and disaster recovery strategies is essential for passing the SAP-C02 exam.
AWS Reliability Principles
The reliability best practices in the AWS Well-Architected Framework are based on five principles. Knowing these principles will help you design resilient and scalable architectures.

Fault Tolerance Attributes
The concepts of no single point of failure and fault isolation are central to understanding fault tolerance. These two attributes form the foundation of fault-tolerant architectures.
No single point of failure: In single point of failure (SPOF) is system vulnerability, where if one component fails the entire system stops functioning. A fault-tolerant system is designed to eliminate SPOF, so that operation can continue even if any component fails. Thus a fault-tolerant system is none point of failure system that provides availability and reliability.
Fault isolation: By limiting the impact of a component failure to a defined boundary, fault isolation prevents a faulty compartment from affecting that part of the system. In this approach, workloads are broken down into small subsystems that fail independently and can be repaired in isolation.
No single point of failure is often the goal of robust reliability design; fault isolation is one of the mechanisms to achieve the goal.
Designing Fault-Tolerant Architecture
AWS provides different architectures to build highly available and reliable infrastructure based on the principles of no single point of failure and fault isolation. One common approach to building fault-tolerant architecture is the distributed system approach.
So, instead of using typical monolithic applications consisting of different layers: a presentation layer, an application layer, and a data layer, you break down the workload into modules or small subsystems that fail independently and can be repaired in isolation. Here are some of the common distributed system architecture:
-
Microservices architecture
-
Multi-AZ architecture
-
Multi-region architecture

Microservices architecture
Microservices architecture breaks an application into independent, modular services. If one service fails, it does not necessarily impact the others because they operate independently.
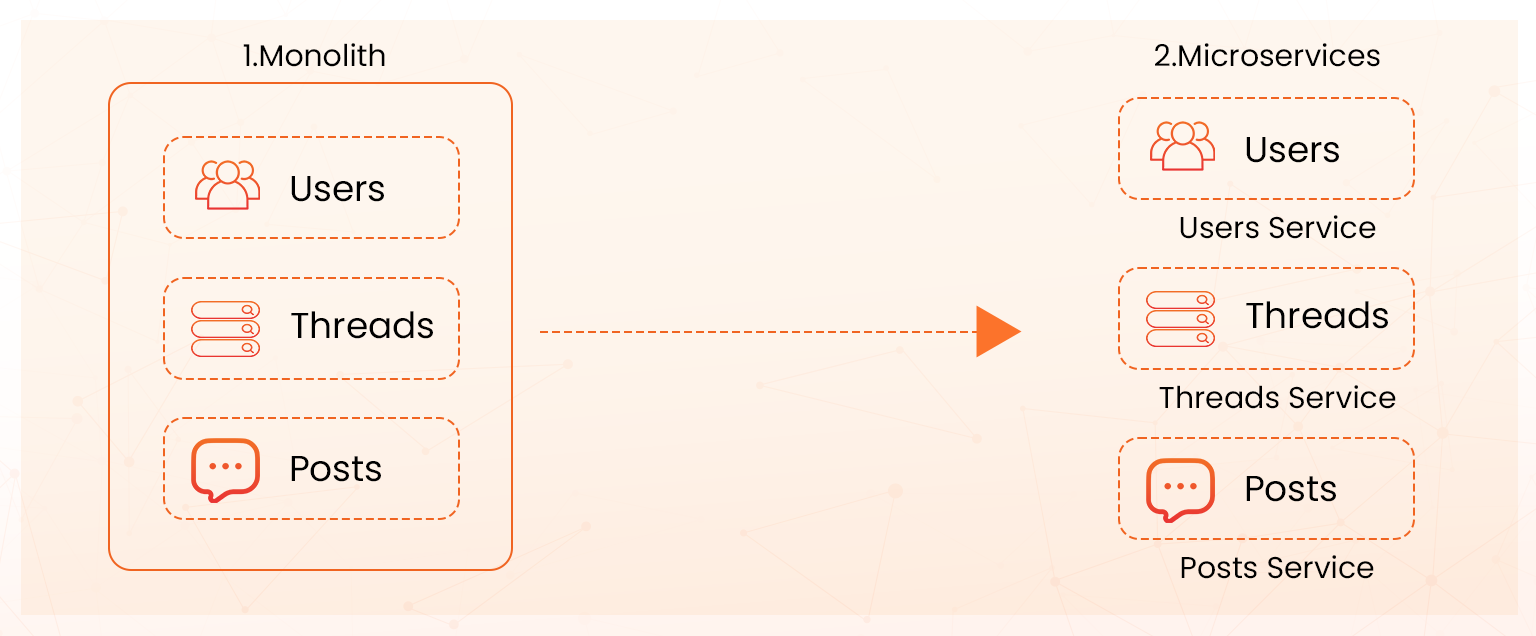
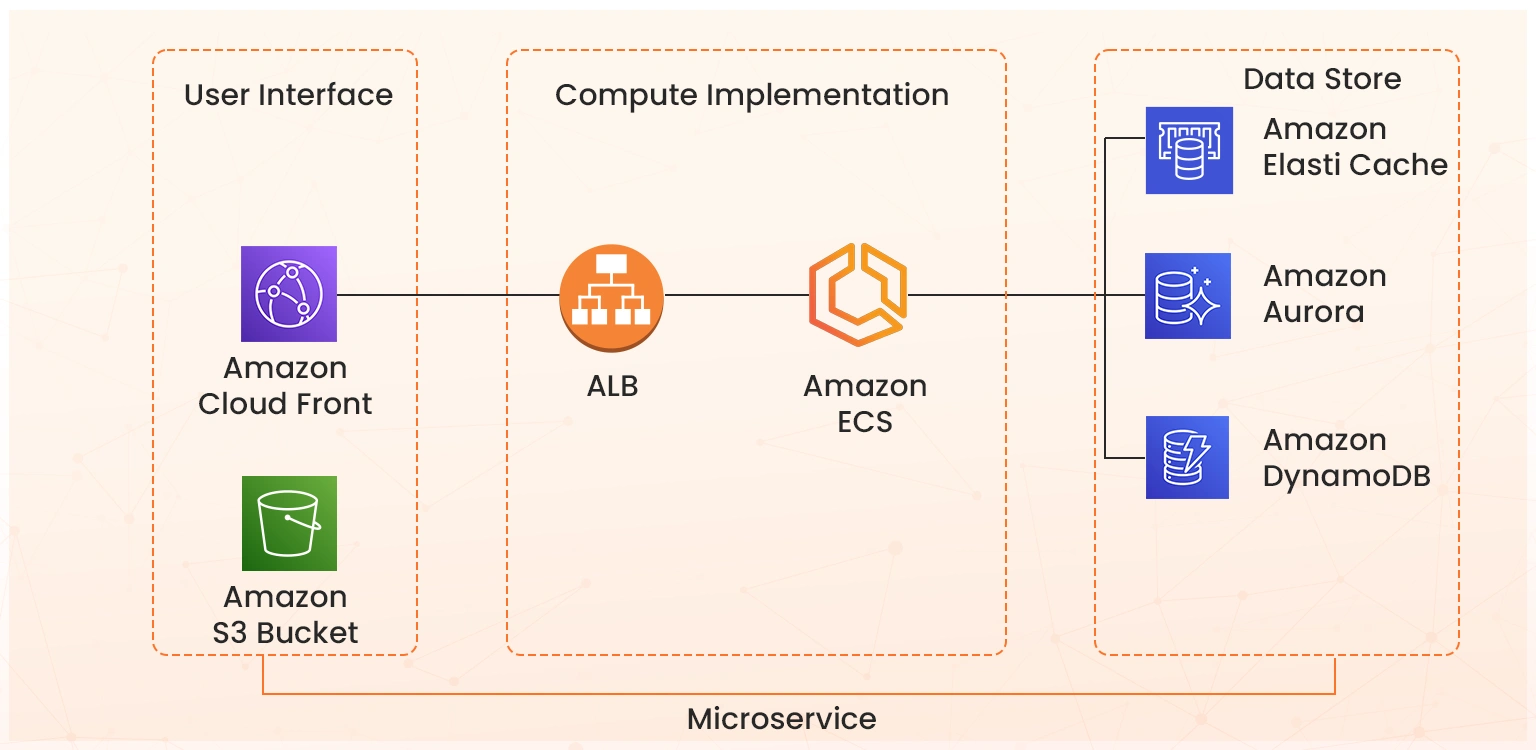
Multi-AZ architecture
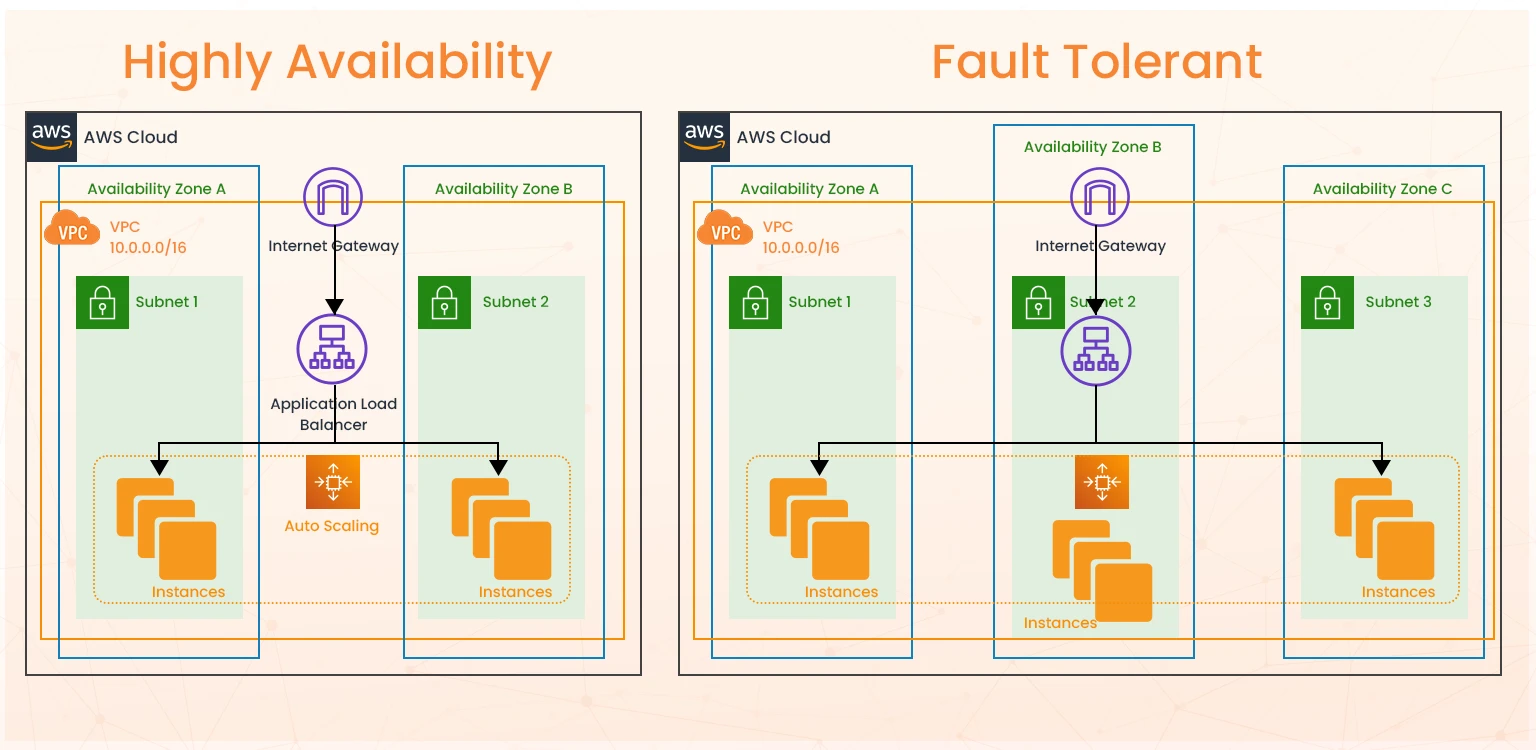
One or more AWS data centers make an AWS Availability Zone—an isolated location within an AWS Region. You can reduce single points of failure and provide highly available applications by distributing your application across multiple AZs.
In general, multiple AZs are commonly used for increased workload redundancy. A multi-AZ architecture replicates resources (such as compute, databases, or load balancers) across multiple Availability Zones within a single AWS Region. If one AZ fails, the workload automatically fails over to the other AZ.
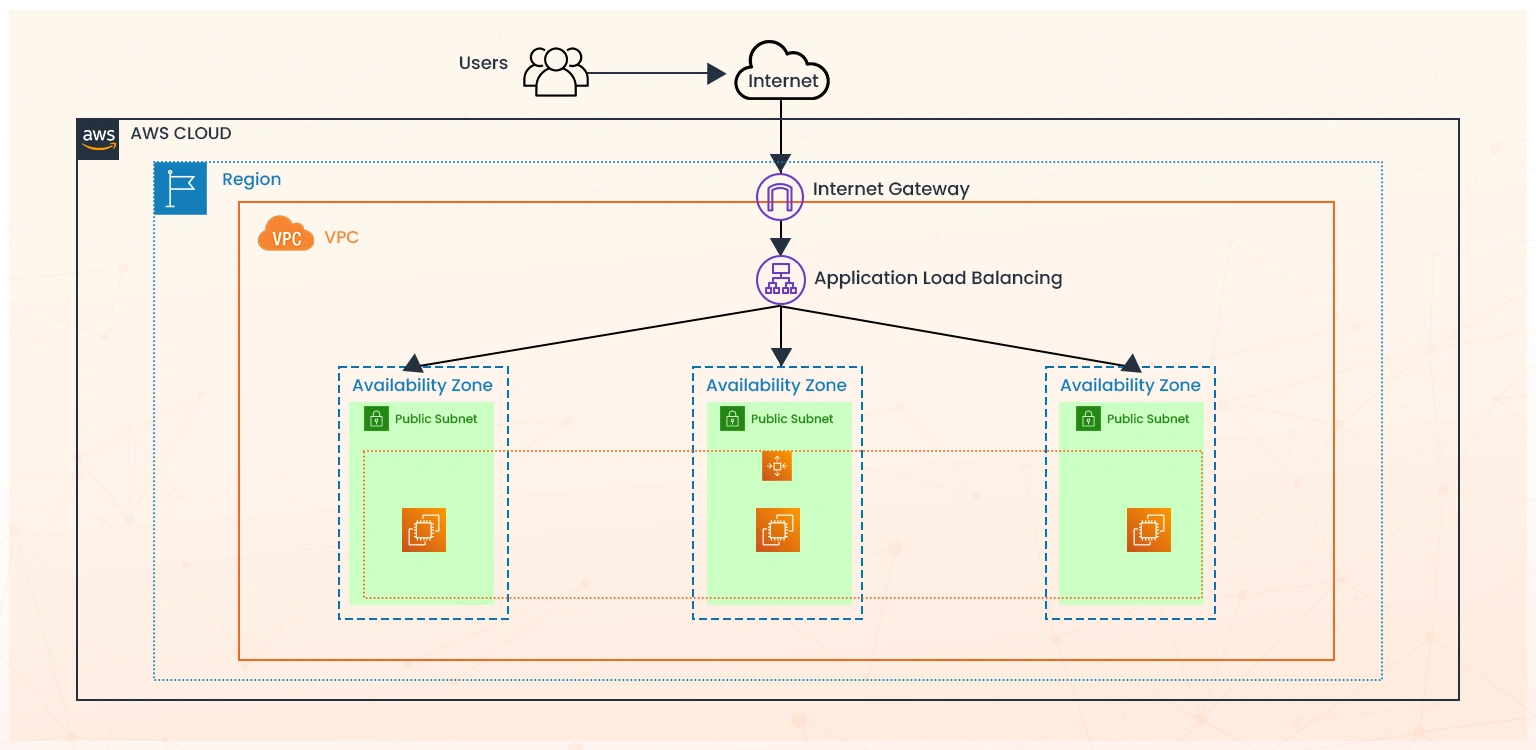
Multi-region architecture
AWS Cloud spans 34 Regions—the broadest geographic category. Each Region is designed to be isolated from the other Regions, enabling the greatest possible fault tolerance and stability. The resources you create in one Region do not exist in any other Region unless you explicitly use an AWS replication feature. The main use cases for multiple AWS Regions is for high availability and disaster recovery. By using a multi-Region architecture, you can replicate resources and workloads across multiple AWS Regions. If an entire Region fails (due to disasters or outages), workloads fail over to another Region to ensure business continuity. Here are some examples of AWS regions, their code, and the availability zones in that region.

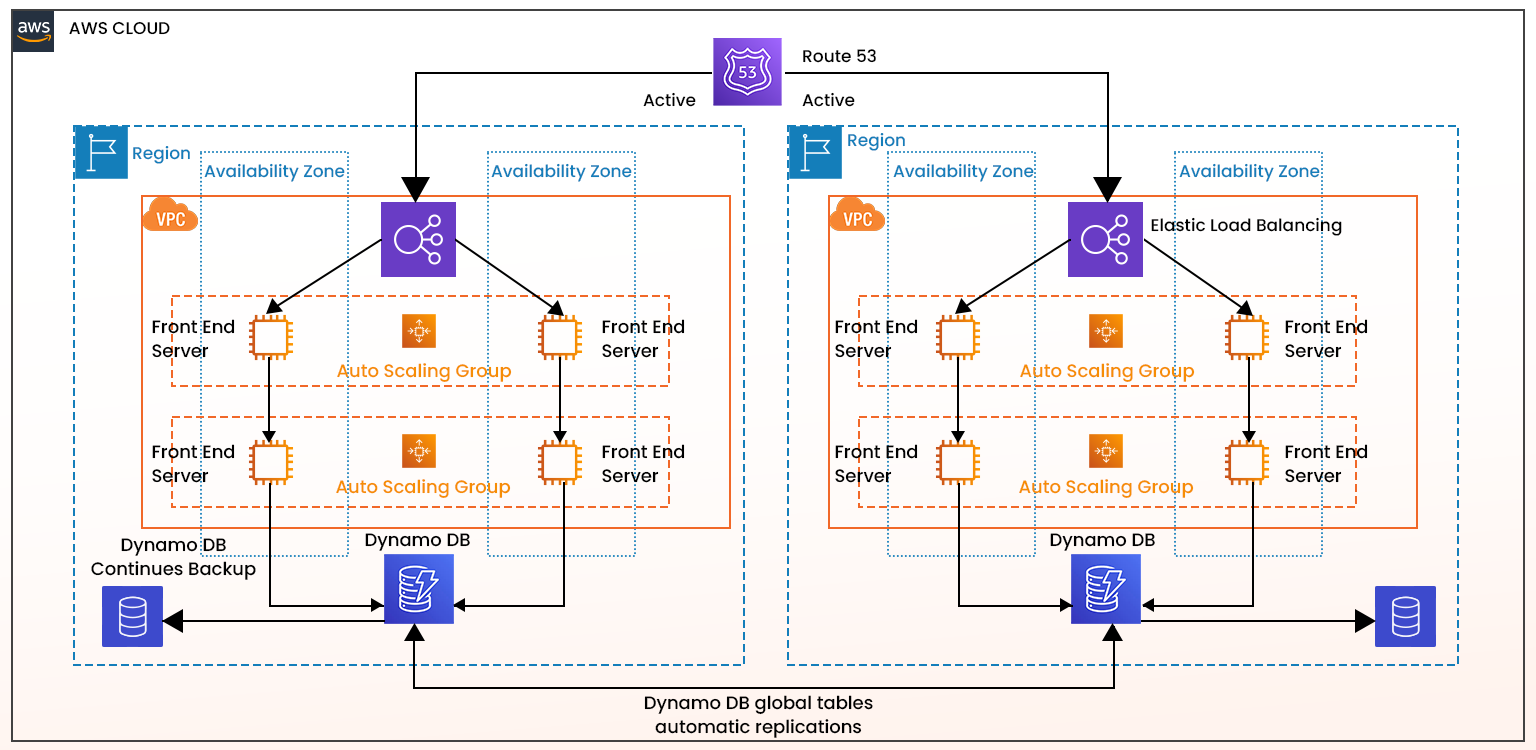
Fault Tolerance vs. Other Aspects of Reliability
As a solution architect, you must understand the different aspects of the AWS reliability pillar to design a strategic approach to reliability. Fault tolerance is closely related to high availability, disaster recovery, and business continuity.
Business continuity: the ability to minimize disruption and continue operations when something unexpected happens
Disaster recovery: the ability to respond to and recover from an event threatens business continuity
High availability: the ability to operate continuously with up to 99.999% availability of applications.
Fault tolerance: the ability to absorb problems without impacting service levels. A Fault Tolerant infrastructure aims for 100% uptime. Therefore, a fault-tolerant application is also considered highly available.
These aspects of the reliability pillar operate under the AWS Shared Responsibility model.
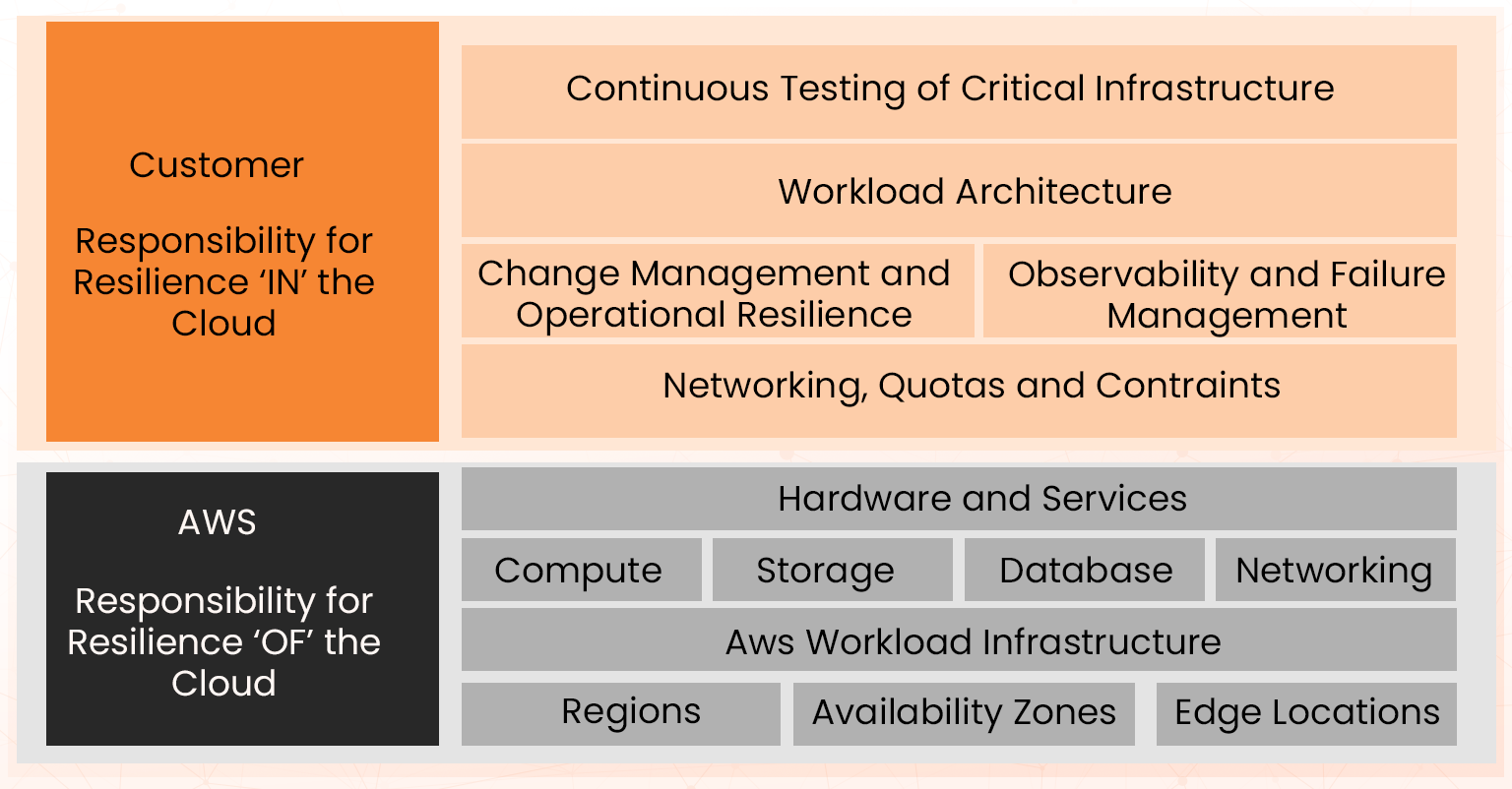
AWS is responsible for the resiliency of the infrastructure that runs all of the services offered in the AWS Cloud. Your customer’s responsibility is determined by the AWS Cloud services they select. As an architect, you should guide customers toward the right combination of AWS services required for a reliable and resilient architecture.
Key AWS Services for Fault-Tolerant System Design
A fault-tolerant system design includes the following components:
- Fault handling: the ability to detect, manage, and mitigate faults
- Failure response: the ability to recover from a failure and main continuity of service and functionality
- Reliability models: the ability to provide availability and disaster recovery and maintain SLA
AWS offers different services such as compute, storage, networking, databases, and others tailored to various components of a fault-tolerant system design. As an architect, you must be able to map the right services to the right components. Here are some examples:

AWS Service Categories for Fault Isolation
Based on their fault isolation boundary, AWS services are grouped into three categories: zonal, Regional, and global. As an architect, you should be able to identify the services that can help withstand localized and regional failures while optimizing costs and performance.
Zonal Services: A zonal service is one that provides the ability to specify which Availability Zone the resources are deployed into. These services operate independently in each Availability Zone within a Region, and more importantly, fail independently in each Availability Zone as well. This means that components of a service in one Availability Zone don’t take dependencies on components in other Availability Zones.
Regional services: Regional services are services that AWS has built on top of multiple Availability Zones so that customers don’t have to figure out how to make the best use of zonal services. AWS logically group the service deployed across multiple Availability Zones to present a single Regional endpoint to customers.
Global services: services that are accessible globally where AWS has a presence.

Fault Tolerance and AWS SLA
A fault-tolerant system enables us to meet or exceed service level agreements (SLAs)—an important tool for managing customer relations. An SLA is an agreed goal or target for a given service on its performance and availability. AWS provides SLA for various services critical for fault tolerance, business continuity, and high availability. SLAs specify the uptime or availability, ensuring businesses can design resilient systems. As an architect, you must keep the SLAs in mind while designing a fault-tolerant architecture. SLAs often include the following components:
- Recovery Time Objective (RTO): Maximum acceptable downtime after a failure.
- Recovery Point Objective (RPO): Maximum acceptable data loss measured in time
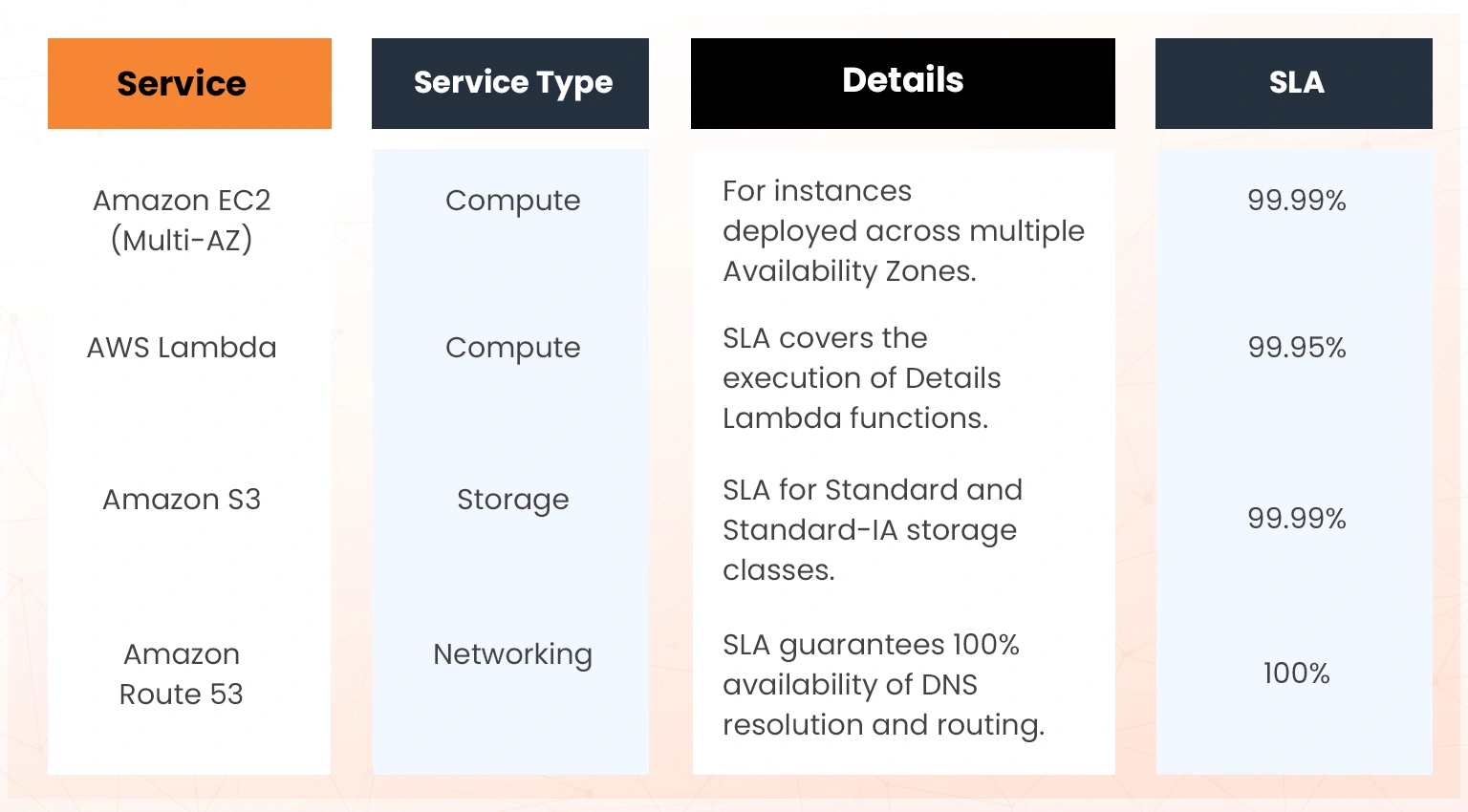
AWS provides detailed SLA documents for its services on its official website. Here are the SLAs of some of the common services for fault tolerance.
Final thoughts
AWS Certified Solutions Architect – Professional (SAP-C02) focuses on reliability and resiliency because they ensure systems run uninterrupted even during expected events. To prepare for the exam, you must thoroughly understand different AWS services and how they integrate to create a robust infrastructure for different fault-tolerant scenarios such as handling AZ failures, ensuring regional backups, and leveraging global services for continuity. You also need hands-on labs for multi-AZ, multi-region solutions. Sign up for the AWS Certified Solutions Architect Professional course to earn this certificate. For additional hands-on experience with the services, check AWS hands-on labs and AWS sandboxes.
- Tableau Data Analyst Salary and Job Trends 2025 - September 30, 2025
- Ultimate Java SE 21 1Z0-830 Preparation Guide for Beginners - September 30, 2025
- Best AWS Certification Courses in 2025 - August 22, 2025
- How to Pass the NVIDIA NCP-ADS Exam in 2025 - July 15, 2025
- Top 10 Topics to Master for the AI-900 Exam - July 10, 2025
- SC-401 Prep Guide: Become a Security Admin - June 28, 2025
- How Does AWS ML Associate Help Cloud Engineers Grow? - June 27, 2025
- Top 15 Must-Knows for AWS Solutions Architect Associate Exam - June 24, 2025
