

This blog is about optimizing ML pipelines that serve as the foundation for constructing and deploying models at scale; their optimization is key. AWS offers a variety of solutions designed to orchestrate machine learning workflows, equipping organizations with a complete set of tools to simplify and automate their ML processes. As a candidate for the AWS Certified AI Practitioner (AIF-C01) exam, you should ensure that you master these techniques, which is crucial.
Optimizing ML pipelines on AWS
There are various considerations steps and processes that can be followed by AI practitioners to effectively optimize ML pipelines on AWS. These include the following;
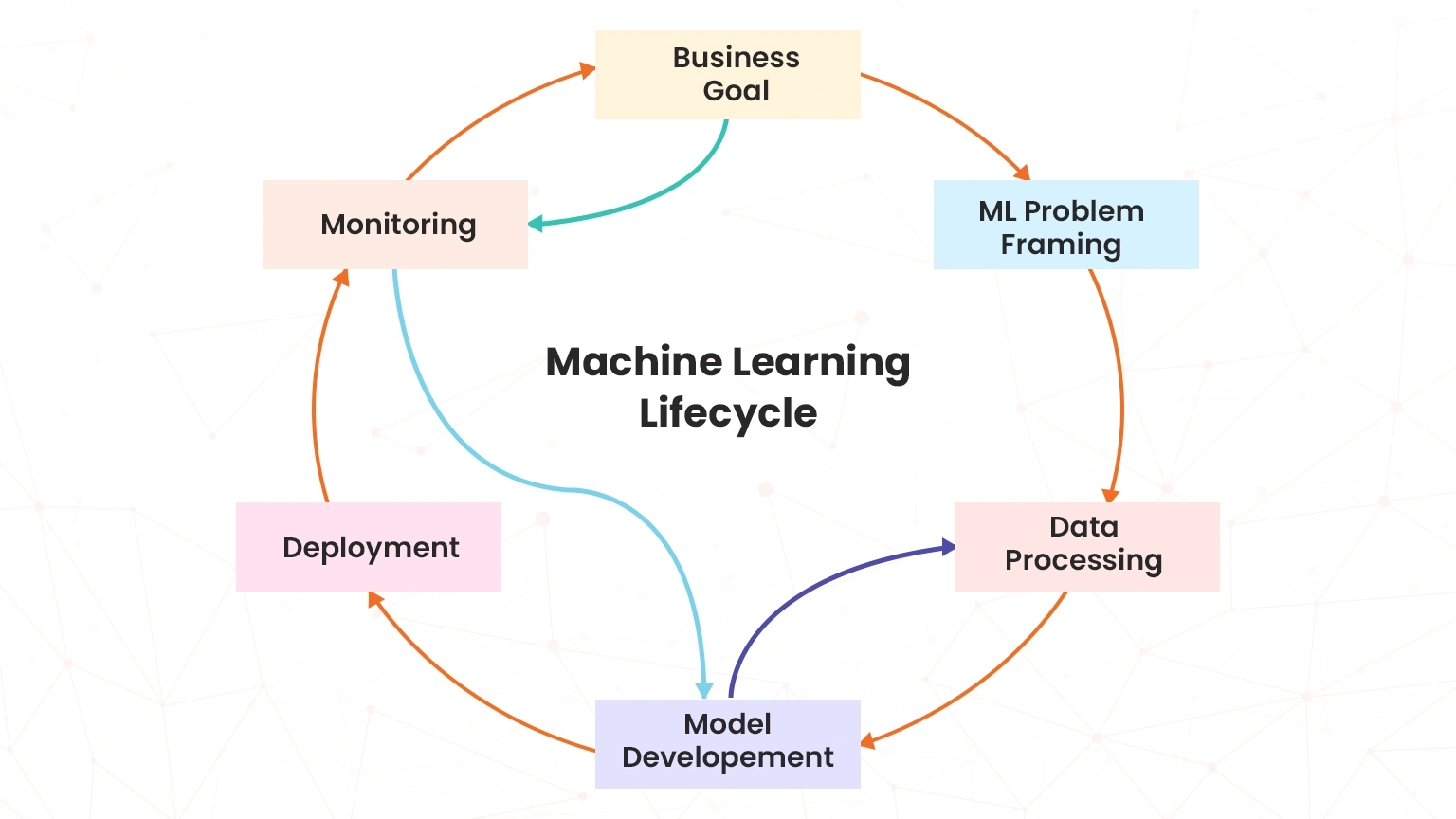
Define Business Goals
It is important to outline the goals, expected outcomes, and performance metrics for your AI/ML model from the onset. Equally important for an AWS Certified AI Practitioner is to work together with stakeholders that are involved in the optimization process. This will ensure that everyone is aware of the expectations of the optimization initiative. Key Performance Indicators (KPIs) such as accuracy and recall scores should also be established to assess the model’s performance.
Define Problem Statement
Before getting into the details, it is important that you clearly understand the problem you’re addressing. Without a clear understanding of the problem, efforts to achieve ML pipeline optimization may all be in vain. A clear problem statement will assist you to keep on track on what really matters in terms of the optimization processes.
Choose the Right Model and Framework
Choosing the right model architecture and ML framework can greatly influence the performance of your pipeline. The use of pre-trained models and transfer learning can help cut down on training time while depending on your specific use case enhances efficiency. As a candidate for the AIF-C01 exam, you also need to select the right compute resources and correct instance type to optimize cost and performance: For example, for;
- Traditional ML models use XGBoost or LightGBM
- Deep learning use TensorFlow or PyTorch
- With massive workloads, you can use Amazon SageMaker Distributed Training with Horovod.
Use Spot Instances & Distributed Training
To reduce training costs and improve scalability you can use Spot Instances and Distributed Training;
- Spot training: Spot Instances in SageMaker can assist in reducing performance and optimizing ML performance by huge margins.
- Distributed training: The Amazon SageMaker Distributed Training allows you to adopt data parallelism for training large dataset training across multiple GPUs.
- Hyperparameter Tuning (HPO): Automate hyperparameter optimization using the SageMaker Automatic Model Tuning functionality within AWS. This will assist you to identify the model that performs best hence leading to performance optimization.
Leverage AWS Managed Services
The good thing about ML is that AWS provides a variety of managed services that make it easier to build, train, and deploy ML models. By using these managed services, you can simplify infrastructure management and concentrate on developing your models. Proficiency in these services is crucial for AI practitioners taking the AWS Certified AI Practitioner exam.
The diagram below shows how to create an end-to-end MLOps pipeline using AWS services such as Amazon SageMaker, Lambda, Step Functions, and Code Pipeline.
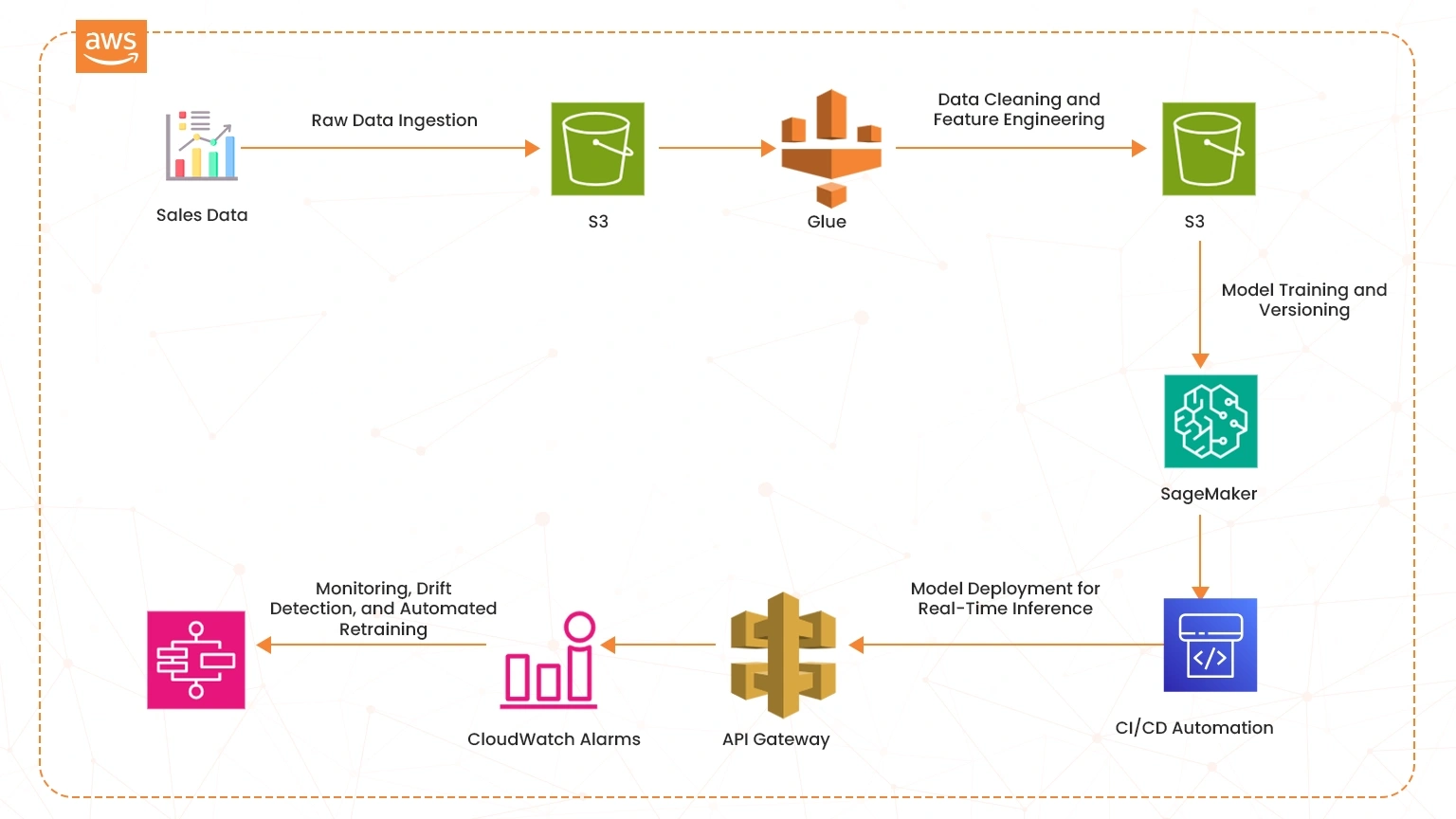
As shown in the diagram above, as the AWS Certified AI Practitioner you should understand how data is ingested and stored in S3 buckets through to where Amazon SageMaker is incorporated to drive the automation of CI/CD pipelines. The process extends to monitoring using tools such as CloudWatch Alarms as well. Note also that Amazon SageMaker supports the following methods in optimizing ML pipelines in AWS;
- Distributed training: Distributed training allows you to train large models more quickly. It achieves this by dividing the training workload among several instances thereby optimizing performance.
- Built-in Algorithms: A range of built-in algorithms that form part of Amazon SageMaker are optimized for performance. These include such algorithms as XGBoost, DeepAR, and Linear Learner. The built-in characteristic means that you do not have to create these algorithms from the ground up which in turn saves time and costs.
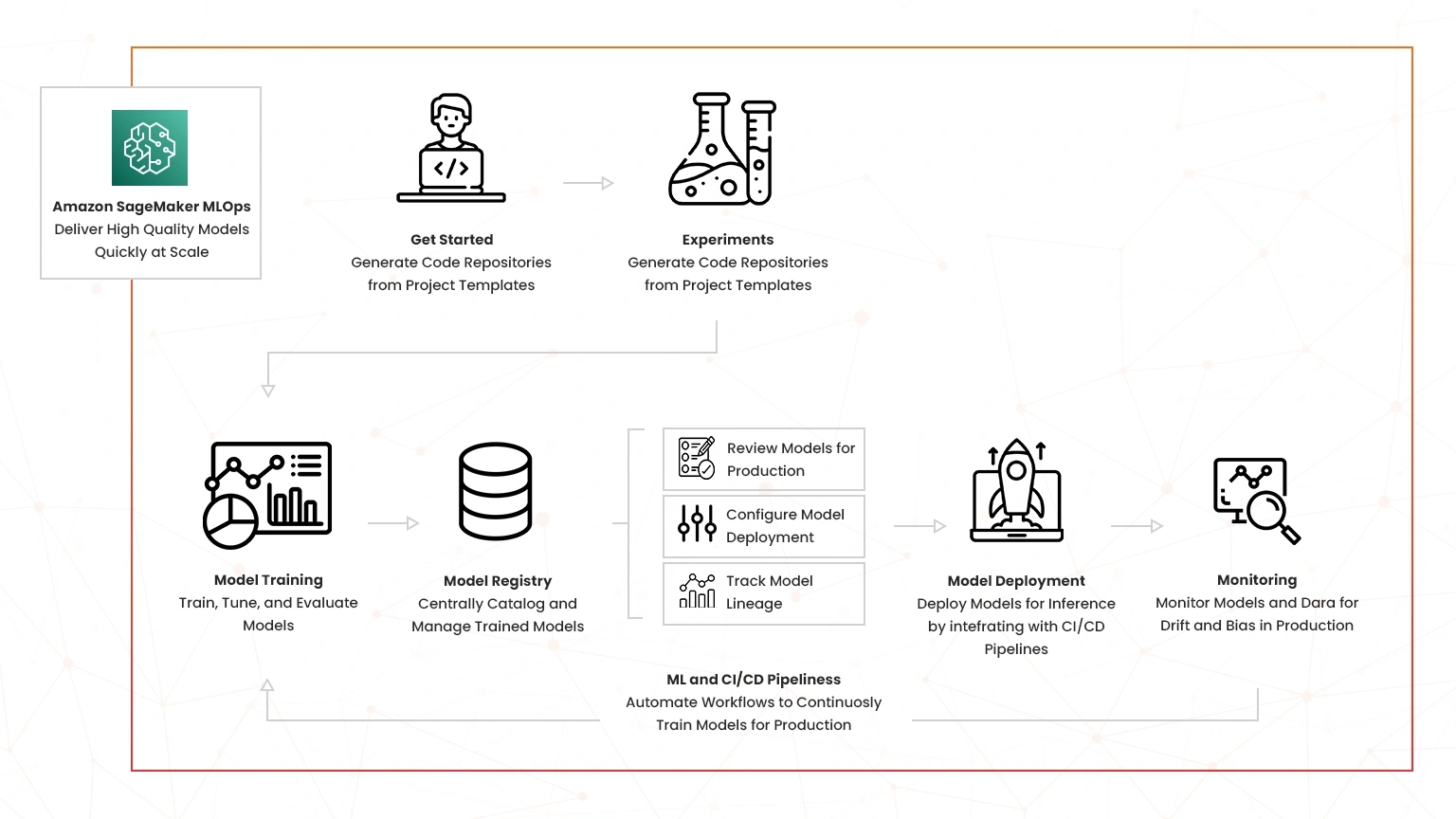
The following diagram shows the various stages followed by Amazon SageMaker in optimizing ML on AWS;
Implement Infrastructure as Code (IaC)
Infrastructure as Code (IaC) and its operations should be well-underwood by candidates intending to sit for the AWS Certified AI Practitioner (AIF-C01) exam. The following IaC solutions are typically used to optimize ML pipelines;
- AWS CloudFormation: This feature allows you to define IaC to ensure consistency across development, staging, and production environments. This enhances efficiency and helps in optimizing ML operations on AWS.
- Version Control: It is crucial that you keep track of infrastructure changes using version control systems. This enables you to rollback to previous configurations if needed.
- Terraform: The use of Terraform allows for the rapid iteration and deployment in ML operations. This functionality allows you to define IaC leading to quicker and optimized deployments. The other advantage is that it facilitates collaboration among team members and streamlines the CI/CD process.
Optimize Data Processing
Efficient data processing is crucial for ML pipelines. You need to ensure that data preprocessing, evaluation, training, and inference are well-defined and integrated into the pipeline to effectively prepare for the AIF-C05 exam. This can be achieved through the following processes;
- Efficient storage solutions: Store raw data in efficient storage solutions such as Amazon Simple Storage Service (Amazon S3). Store large datasets in Amazon S3 for scalable and durable storage using the appropriate storage classes. This ensures faster data access as well as cost savings.
- Interactive Analysis: Use Jupyter Notebooks for interactive data exploration, enabling quick iteration and visualization of data preprocessing steps. Also manage and version dataset features across different ML projects to further enhance performance.
- Inter–region data transfers: It is also crucial to store data within the same AWS Region. Avoiding inter-region transfer costs will result in significant cost reductions in the long-term.
Utilize Model Parallelism Techniques
A key aspect to note here is that ML training workflows typically require significant preprocessing and transformation operations. For large-scale AI models, model parallelism techniques can enhance performance and efficiency.
- Tensor partitioning: splits tensors across devices to minimize memory usage and maximize computational efficiency. AWS provides tools such as Amazon Elastic Kubernetes Service (EKS) to manage clusters of computing resources efficiently.
- Kubernetes clusters: Manage clusters of computing resources efficiently with Amazon EKS, which simplifies the deployment of containerized applications.
- AWS Glue: Use AWS Glue functionality to enhance the distributed preprocessing of large datasets. You can also integrate AWS Glue with Amazon SageMaker for optimizing feature engineering pipelines.
- Amazon EMR: if you are working with Big Data ML pipelines, you need to leverage Amazon EMR functionalities such as Apache Spark, Hive, or Presto. This enables you to autoscale compute instances to optimize performance.
- AWS Lambda: The use of AWS Lambda and Step functions for event-driven Pipelines helps optimize performance of the entire ML pipelines on AWS. AWS Lamba is effective for lightweight preprocessing such as filtering, feature extraction while AWS Step Functions can be used to orchestrate multi-step ETL workflows.
Implement CI/CD Pipelines
You can also integrate ML development workflows with deployment workflows to rapidly deliver new models for production applications. Amazon SageMaker Projects brings CI/CD practices to ML, such as maintaining parity between development and production environments, source and version control, A/B testing, and end-to-end automation. You should also endure that you deploy a model to production as soon as it is approved as this enhances model agility. The implantation of CI/CD pipeline should also take into consideration the following variables;
- Endpoint availability: Amazon SageMaker offers built-in safeguards to help you maintain endpoint availability and minimize deployment risk and takes care of setting up and orchestrating deployment best practices. Such practices include such as Blue/Green deployments to maximize availability and integrate them with endpoint update mechanisms, such as auto rollback mechanisms, to help you automatically identify issues early and take corrective action before they significantly impact production.
- Amazon SageMaker Pipelines: Use this functionality to reduce the risk of errors and provide faster feedback loops. It involves automated testing, continuous deployment, and model packaging and containerization which are key components of an effective CI/CD pipeline. CI/CD pipelines into your workflow can significantly enhance the speed and quality of ML applications. It is also a key concept tested in the AIF-C01 exam.
- AWS CodePipeline: To ensure smooth ML optimization, automate CI/CD integration with other functionalities such as SageMaker, Lambda though the AWS CodePipeline. Incorporate automated testing to provide continuous feedback, ensuring that your models are always in a deployable state.
Optimize Communication Protocols
Efficient communication protocols are essential for maintaining high training speeds. Utilize protocols such as NVIDIA’s NCCL or MPI to facilitate quick data transfer between devices. Reducing communication overhead ensures that the computational workload is evenly distributed and prevents bottlenecks. Use these protocols to facilitate quick data transfer between devices, reducing communication overhead and preventing bottlenecks in distributed training.
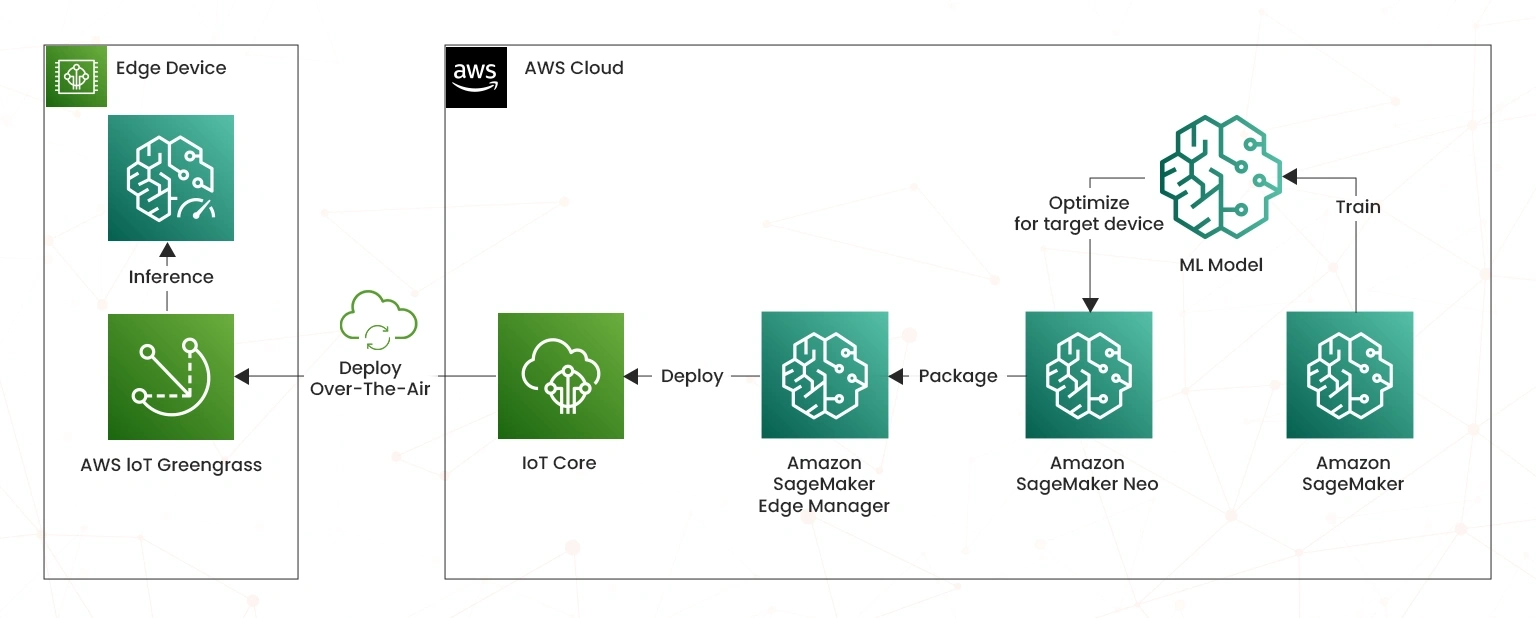
Consider inference at the edge
Working with the Internet of Things (IoT) presents unique challenges with optimizing ML in AWS. One of the best options that you can adopt is to evaluate if ML inference at the edge can reduce the carbon footprint of your workload. This involves a thorough consideration of a variety of factors including the compute capacity of your devices, their energy consumption, or the emissions related to data transfer. Note that optimizing model inference is key for cost savings and most appropriate for those organisations that deploy a wide range of low-traffic models. Diagram below shows the placement of inference operations are the edge of the AWS cloud environment;
Ensure Fault Tolerance
To optimize ML model performance, it is important to implement mechanisms such as following to enhance fault tolerance. These include the following;
- Checkpointing: This functionality ensures that in the event of a failure, training can resume without significant loss of progress. This is vital for maintaining the reliability and robustness of ML pipelines.
- Amazon S3 Glacier: Deploy S3 Glacier to save the state of the model at regular intervals. This supports long-term model checkpointing, allowing training to resume without significant loss of progress in case of failures.
Security and Compliance
Security is paramount when dealing with sensitive data and AI/ML models. Cloud platforms offer various tools and features to help you maintain security and compliance including the following,
- Encrypt data at rest, in process and in transit using tools such as AWS KMS.
- Deploy AWS Shield and Web Application Firewall (WAF). This assists in protecting DDoS attacks.
- Implement Role-Based Access Control (RBAC) and AWS IAM. This allows you to limit permissions to your ML models as well as reducing the attack surface.
- Enforce compliance with regulations and standards. These include GDPR, HIPAA and PCI -DSS as applicable to the model’s operating environment.
Monitor and Optimize Continuously
AI/ML pipelines are dynamic and require ongoing optimization to adapt to changing data and workloads. The monitoring aspects consists of use of monitoring tools and retraining activities;
- Monitoring tools. Regularly review pipeline performance metrics at regular intervals to identify points when performance falls below requirements. Monitoring can be enhanced through the deployment of monitoring tools such as Prometheus and Grafana for real-time monitoring. You can also use tools such as Amazon CloudWatch & Amazon SageMaker Model Monitor to detect model drifts and changes in latency.
- Retraining: Because of model drift, robustness, it is possible to gains new avenues for truth data. This may require the models to be retrained using the new data. Rather than retraining the model on an arbitrary basis, you should instead monitor your ML model in production to automate your model drift detection. As an AWS Certified AI Practitioner, you should only consider retraining when the model’s predictive performance falls below defined KPIs.
Conclusion
In summary, optimizing AI/ML pipelines on cloud platforms is a continuous process that involves the planning and application of a variety of technologies to achieve the required performance gains. AI practitioners preparing for the AWS Certified AI Practitioner (AIF-C01) exam should be able to optimize ML pipelines on AWS, enhancing performance, efficiency, and reliability using a variety of methods. You can gain these skills through hands-on training like hands-on labs and Sandboxes. Talk to our experts in case of queries!
- Tableau Data Analyst Salary and Job Trends 2025 - September 30, 2025
- Ultimate Java SE 21 1Z0-830 Preparation Guide for Beginners - September 30, 2025
- Best AWS Certification Courses in 2025 - August 22, 2025
- How to Pass the NVIDIA NCP-ADS Exam in 2025 - July 15, 2025
- Top 10 Topics to Master for the AI-900 Exam - July 10, 2025
- SC-401 Prep Guide: Become a Security Admin - June 28, 2025
- How Does AWS ML Associate Help Cloud Engineers Grow? - June 27, 2025
- Top 15 Must-Knows for AWS Solutions Architect Associate Exam - June 24, 2025
