
As a Professional Google Cloud Developer you will build scalable applications on Google cloud environment. This is an intermediate exam based on Google cloud practices and tools. Google recommends 3+ years of working experience in which one year should be in the Google Cloud environment. It would be an easy exam for you if you are an experienced developer.
This 25 questions practice exam is based on the real Google Cloud developer exam format and helps you develop an understanding of what kind of questions to expect. If you want to practice more, check our free practice exam.
Google Cloud Certified Professional Cloud Developer Exam Questions
Designing highly scalable, available, and reliable cloud-native applications
Q 1. A client of yours has asked you for advice because he is looking for a quick and convenient solution for adding functionalities to an Application.
Whenever a new customer is created in the Firebase database, he wants to perform a series of welcome activities and a series of follow-up actions, regardless of the specific function that recorded the new customer record.
Which of the following solutions will you suggest (choose 1)?
A. Compute Engine and Managed Instances
B. App Engine Flexible Environment
C. App Engine Standard Environment
D. Cloud Functions
E. Cloud Run (fully managed)
Correct Answer: D
Any of these environments can host the additional functionalities required.
The best solution is with Cloud Function, because you can handle events in the Firebase Realtime Database with no need to update client code.
Cloud Functions may have the full administrative privileges to ensures that each change to the database is processed individually.
Furthermore Cloud Functions are a decoupled economic solution, because of the pay-as-you go model.
Functions handle database events in 2 ways; listening for specifically for only creation, update, or deletion events, or you can listen for any change of any kind to a path.
These Cloud Functions event handlers are supported
- onWrite(), which triggers when data is created, updated, or deleted in the Realtime Database.
- onCreate(), which triggers when new data is created in the Realtime Database.
- onUpdate(), which triggers when data is updated in the Realtime Database.
- onDelete(), which triggers when data is deleted from the Realtime Database.
Q 2. A team of mobile developers is developing a new application. It will require synchronizing data between mobile devices and a backend database. Which database service would you recommend?
A. Cloud SQL
B. BigQuery
C. Firestore
D. Spanner
E. Bigtable
Correct Answer: C
Firestore, part of GCP and of Firebase is the only Database designed for Web and Mobile applications that provides live synchronization and offline support,
Cloud Firestore is a fast, fully managed, serverless, cloud-native NoSQL document database that simplifies storing, syncing, and querying data for mobile, web, and IoT apps at global scale.
Cloud Firestore is the next generation of Cloud Datastore. So Datastore is just the same of Firestore.
Q 3. You are migrating a series of applications to Google Cloud Platform with a lift and shift methodology, using Compute Engine.
Applications must be scalable, so Load Balancer and instance groups are being configured.
Some applications manage session data in memory.
Which of the following configurations do you choose to allow apps to work properly?
A. HTTP(S) load balancer with Session affinity
B. HTTP(S) load balancer with WebSocket proxy support
C. QUIC protocol support for HTTPS Load Balancing
D. Network Load Balancing
E. SSL Proxy con Health Checks
Correct Answer: A
Session affinity provides a best-effort attempt to send requests from a particular client to the same backend for as long as the backend is healthy and has the capacity, according to the configured balancing mode.
It is the best way to assure that session data is maintained in memory.
It is a feature of the HTTP(S) load balancing.
Google Cloud SSL Proxy Load Balancing terminates user SSL (TLS) connections at the load balancing layer, then balances the connections across your instances using the SSL or TCP protocols. Cloud SSL proxy is intended for non-HTTP(S) traffic. For HTTP(S) traffic, HTTP(S) load balancing is recommended instead.
pass-through load balancer, so your backends receive the original client request
Q 4. You work in an international Company based in North America and your boss told you that you have to plan the GDPR compliance for EUROPE.
Which of the following elements you have to take care of?
A. Create an updated inventory of personal data that you handle.
B. Let the common data to be public, if the Customer doesn’t advice against
C. Use California Consumer Protection Act (CCPA) rules
D. Review your current controls, policies, and processes for managing and protecting data
Correct answers: A, D
The General Data Protection Regulation (EU) 2016/679 (GDPR) is a regulation in EU law on data protection and privacy in the European Union (EU) and the European Economic Area (EEA). It also addresses the transfer of personal data outside the EU and EEA areas. The GDPR aims primarily to give control to individuals over their personal data and to simplify the regulatory environment for international business by unifying the regulation within the EU.
B is wrong because GDPR protects privacy, so it is against of unsolicited distribution of private information
B is wrong because CCPA are different
Q 5. You are responsible for planning the migration to GCP of an important application that works with Oracle Database.
A horizontally scalable and globally functioning SQL database is required.
Which service is better to use and which type of schema migration is recommended?
A. Cloud SQL with no schema migration
B. Cloud SQL with sequential primary keys migration
C. Cloud Spanner with no schema migration
D. Cloud Spanner with sequential primary keys migration
Correct Answer: D
The requirements point to an SQL Database that is global and distributed with synchronized replicas and shards in multiple Servers: Cloud Spanner.
The risk of hotspotting with synchronized replicas needs to be addressed; that is updates that are not distributed among multiple servers.
So it is necessary to be careful not to create hotspots with the choice of your primary key. For example, if you insert records with a monotonically increasing integer as the key, you’ll always insert at the end of your key space. This is undesirable because Cloud Spanner divides data among servers by key ranges, which means your inserts will be directed at a single server, creating a hotspot.
The techniques that can spread the load across multiple servers and avoid hotspots:
Hash the key and store it in a column. Use the hash column (or the hash column and the unique key columns together) as the primary key.
Swap the order of the columns in the primary key.
Use a Universally Unique Identifier (UUID). Version 4 UUID is recommended, because it uses random values in the high-order bits. Don’t use a UUID algorithm (such as version 1 UUID) that stores the timestamp in the high order bits.
Bit-reverse sequential values.
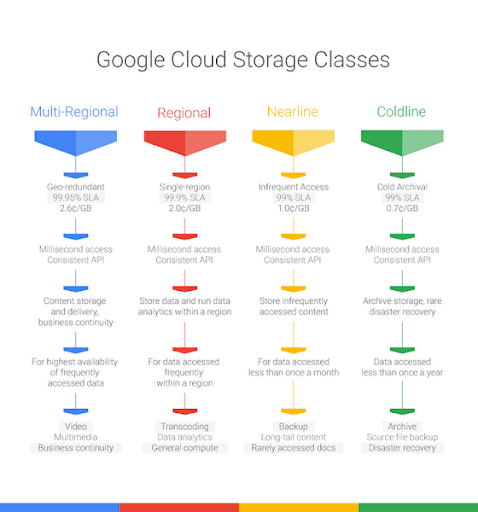
Q 6. With Cloud Storage, you may have different classes and it is possible to pass from one class to another.
But some transitions are not allowed.
Which one of the following is not possible?
A. Regional to nearline
B. Multiregional to coldline
C. Regional to multiregional
D. Nearline to coldline
Correct Answer: C
When you create a bucket you have to declare if it will be either regional or multiregional,
You cannot change afterward.
All the other transitions are allowed.
Q 7. You are looking for a SQL system to integrate and query both historical and production data.
The data must be organized in complex structures. In particular, it is necessary to store orders and invoices in a denormalized and complete manner with the header and detail within the same structure.
Which of the following products do you choose?
A. Cloud Datastore
B. Cloud Spanner
C. Cloud Bigtable
D. BigQuery
E. Cloud SQL
Correct Answer: D
BigQuery is an OLAP engine. So, it is far better, even if it can manage normalised data and joins, to have denormalized information.
In addition BigQuery can manage nested and repeated columns and structures, as required.
BigQuery is not a Database but an enterprise, serverless, highly scalable, and cost-effective cloud data data warehouse that solves this problem by enabling super-fast SQL queries using the processing power of Google’s infrastructure.
It can quickly analyze gigabytes to petabytes of data using ANSI SQL.
Building and Testing Applications
Q 8. You are the leader of a development group that is migrating some applications to the Cloud and who has asked you how to set up a local work environment.
In the company they need to use specific development tools that are installed on the Clients.
Which of these tips would you provide?
A. Develop locally by making remote calls to services with credentials within the code
B. Develop remotely with the setup of a VM with Compute Engine and a Development Disk Image
C. Use Cloud Shell
D. Install Cloud SDK and use Service Accounts
Correct Answer: D
A is wrong because you are not connecting to the services and it is not advisable to credentials within the code
B is wrong because it is terribly expensive and complex; moreover, it is not local
C is wrong because it is a feasible way, but not local
D is correct because Cloud SDK is scoped to this very aim and Service Accounts are the Google recommended practice for authorization
Q 9. You are the leader of a development group; you want to start using Continuous Integration and Deployment Techniques and you care to organize procedure in the best way.
In your company you are not allowed to publish code in public or not internally certified Sites.
Where will the code developed by your team be stored and shared?
A. Cloud Storage with versioned Objects
B. Github
C. Cloud Source Repository
D. AppEngine and Blue green Integration
Correct Answer: C
Google Cloud Source Repositories are private, fully featured, scalable Git repositories hosted on Google Cloud Platform.
Git is a program that monitors files and tracks changes. A Git repository:
- Tracks any updates
- Registers a history
- May trigger actions
A is wrong because Cloud Storage only registers the complete versions of the files.
B is wrong because Github is a Git repository but not private or not internally certified.
D is wrong because AppEngine is not a Git repository and Blue green is a kind of deployment, not source integration tool.
Q 10. You are the leader of a development group; you want to start using Continuous Integration and Deployment Techniques and you care to organize procedure in the best way.
In your company the new trend is to deploy apps and services within containers. The idea is to use Kubernetes.
You want to start the deployment as soon as new Source is committed.
Which product is the best suitable one for creating Docker images from code?
A. Cloud Build
B. Cloud Code
C. Cloud Tasks
D. Cloud Repositories
E. Cloud Run
Correct answer: A
Cloud Build can define workflows for building, testing, and deploying across multiple environments such as VMs, serverless, Kubernetes, or Firebase.
B is wrong because Cloud Code is an integrated set of tools to help write, deploy, and debug cloud-native applications. It as extensions to IDEs such as Visual Studio Code and IntelliJ are provided to let rapidly iterate, debug, and deploy code to Kubernetes.
C is wrong because Cloud Tasks is an asynchronous task execution service that encode and execute Tasks using Queues.
D is wrong because Cloud Repositories are Git source repos.
E is wrong because Cloud Run is a serverless platform for containerized applications.
Q 11. The management asked you, as project leader of the development, to prepare a plan with the organizational proposals for the migration of corporate apps to the cloud, both as development projects and as an operational strategy.
What do you propose for the new organization of development?
A. Create small groups with scrum master
B. No changes: keep on consolidated methods
C. Decentralize development and use offshore development
D. Maintain the current organization and modernize the deployment
Correct Answer: A
In order to improve and modernize software development, it is advisable to adopt Agile.
Agile software development organized requirements and solutions through the collaborative effort of self-organizing and cross-functional teams and their customer/end user.
It aims at adaptive planning, evolutionary development, early delivery, and continual improvement.
Scrum is one of the most known agile process frameworks for managing complex knowledge work.
Q 12. You have this SQL Statement in Bigquery:
SELECT ANY_VALUE(fruit) as any_value
FROM UNNEST([“apple”, “banana”, “pear”]) as fruit;
What is the result of this query?
A. a table with 3 rows
B. Apple
C. Banana
D. Pear
E. one of the values, randomly
Correct Answer: E
The interesting elements in this query are:
- UNNEST: takes an ARRAY and returns a table, UNNEST may be used outside of the FROM clause with the IN operator
- Analytic Functions: a function that computes aggregate values over a group of rows.
- ANY_VALUE function that returns a random value from the input or NULL if there are zero input rows
So, from the table created on the fly from an array, you may pick a casual value each time you execute the query.
A more complex statement is:
SELECT fruit,
ANY_VALUE(fruit) OVER (ORDER BY LENGTH(fruit) ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS any_value
FROM UNNEST([“apple”, “banana”, “pear”]) as fruit;
In the reference, you will find a complete explanation.
Deploying applications
Q 13. You set up an application to be deployed in a Kubernetes Cluster with GKE. Your app uses various Cloud services, including Cloud Spanner and Cloud Pub / Sub and you are requested to find an optimized way to run the system.
What is the best way to securely authorize all operations?
A. Write the login credentials of a user enabled to those Services in the Deployment manifest file in YAML format
B. Associate a specific service account with the configuration of the specific node pool (NodeConfig)
C. Create a service account and use the corresponding key with a K8s secret
D. Write the credentials in the source repository or inside the container image
Correct Answer C
A and D are wrong because you are never advised to write the credentials, in the code or in some configuration file and so, expose security information in clear text.
The best method is always through the use of Service Accounts.
You can configure the Service Account to be associated each time a VM is created, but the privileges to be assigned can be different among the various applications in the various pods that may share the same VM. So option B is not the best one.
In order to configure a Service Account for each pod, obeying the principle of least privilege, you may follow this procedure:
- Create the Service Account, configure the Necessary Permissions and create a Service Account Key
- Store the Service Account Key, supplied in a service-account.json file, in a Kubernetes Secret
- Access the Service Account key using the GOOGLE_APPLICATION_CREDENTIALS environment variable to point at the json file inside the secret volume.
Kubernetes secret objects let you store and manage sensitive information, such as passwords, OAuth tokens, and ssh keys. Putting this information in a secret is safer and more flexible than putting it verbatim in a Pod definition or in a container image.
A Kubernetes volume is just a directory, possibly with some data in it, which is accessible to the Containers in a Pod.
Q 14. You have an application that examines the written requests of a Customer Care in order to prepare examples of ready-made answers in the operator assistance system.
The problem is that sometimes within the dialogues confidential information is transcribed that should not be disclosed.
What is the most easy and immediate GCP technique to adopt in the program that processes these texts?
A. Use Cloud Data Loss Prevention
B. Use Dialogflow
C. Create a Python app with a list of the sensitive data/words to be detected
D. Use Cloud Natural Language API
Correct Answer A
Cloud Data Loss Prevention (DLP) is the perfect and ready to use solution; it uses information types—or infoTypes—to define what it scans for. An infoType is a type of sensitive data, such as name, email address, telephone number, identification number, or credit card number.
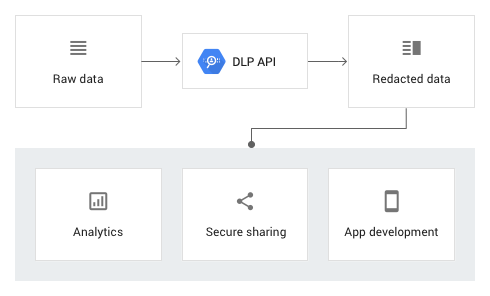
Every infoType defined in Cloud DLP has a corresponding detector. Cloud DLP uses infoType detectors in the configuration for its scans to determine what to inspect for and how to transform findings. InfoType names are also used when displaying or reporting scan results.
There are a large set of pre-ready infoTypes but it is possible to develop and create Custom infoType detectors.
B is wrong because Dialogflow is an end-to-end, build-once deploy-everywhere development suite for creating conversational interfaces for websites, mobile applications, popular messaging platforms, and IoT devices. You can use it to build interfaces (such as chatbots and conversational IVR) that enable natural and rich interactions between your users and your business. Dialogflow Enterprise Edition users have access to Google Cloud Support and a service level agreement (SLA) for production deployments.
C is wrong because it is a long, error prone and difficult to maintain solution.
D is wrong because the Cloud Natural Language API provides natural language understanding technologies to developers, including sentiment analysis, entity analysis, entity sentiment analysis, content classification, and syntax analysis. This API is part of the larger Cloud Machine Learning API family.
It is not directly aimed at sensitive data detection.
Q 15. You are going to deploy a set of applications in GKE.
Which of the following choices do you need to make to be sure that the application will not have Single Point of failures of any kind and will be scalable?
Choose 2 options among the following ones?
A. Create a cluster with a default-pool with cluster autoscaler
B. Create a single-zone cluster
C. Create a cluster with a default-pool with a default configuration
D. Create a regional cluster
Correct Answer A, D
In order to avoid Single Point of failures of any kind, you have to have
- workers nodes with auto-healing and auto-scaling
- Option A
- a backup master node (regional cluster).
- Option D
Nodes execute the workloads run on the cluster. Nodes are VMs that run containers configured to run an application. Nodes are primarily controlled by the cluster master, but some commands can be run manually. The nodes run an agent called kubelet, which is the service that communicates with the cluster master.
A single-zone cluster has a single control plane (master) running in one zone. This control plane manages workloads on nodes running in the same zone.
Multi-zonal clusters
A multi-zonal cluster has a single replica of the control plane running in a single zone, and has nodes running in multiple zones. During an upgrade of the cluster or an outage of the zone where the control plane runs, workloads still run. However, the cluster, its nodes, and its workloads cannot be configured until the control plane is available. Multi-zonal clusters balance availability and cost for consistent workloads. If you want to maintain availability and the number of your nodes and node pools are changing frequently, consider using a regional cluster.
Regional clusters
A regional cluster has multiple replicas of the control plane, running in multiple zones within a given region. Nodes also run in each zone where a replica of the control plane runs. Because a regional cluster replicates the control plane and nodes, it consumes more Compute Engine resources than a similar single-zone or multi-zonal cluster.
Q 16. Your team set up the standard VM configuration for a group of applications and prepared a template.
Everything is working just fine.
Now the traffic is increasing and you want everything to be more scalable, high available and secure.
What is the very first action to take?
A. For next VM you put the –scalable parameter in the template
B. Set up a Load Balancer
C. Take a snapshot of the boot disk
D. Set up a managed instance group
Correct Answer: D
The managed instance group (MIG) gives you high availability: If an instance stops, crashes, is malfunctioning or is deleted by an action other than an instance group management command, the MIG automatically recreates that instance in accordance with the original instance’s specification.
Managed instance groups support autoscaling that dynamically adds or removes instances. You have to setup a Load Balancer in front of the MIG
A is wrong because there is not a –scalable parameter
B is wrong because you have to set up first a MIG
C is wrong because is not what is required
Q 17. You want to have more control over your Cloud GCP VMs. In particular, you want to optimize performance and find the optimal configuration so that your applications are always blazing fast and available.
You are looking for detailed Disk and Memory metrics and the statistics that you usually collect with the “collectd” Linux command.
Which function can you activate and how?
A. Stackdriver Monitoring agent
B. Cloud Armor
C. Nothing: GCP Console alone supply anything
D. You must use a third party tool to have an advanced monitor
Correct Answers: A
The Stackdriver Monitoring agent is a collectd-based daemon that gathers system and application metrics from virtual machine instances and sends them to Monitoring.
Metrics help understand how applications and system services are performing.
Stackdriver can monitor GCP, AWS, and third-party software.
Standard Stackdriver Monitoring can access some instance metrics, but using the Monitoring agent (optional ) you can define and gather all the data you need.
By default, the Monitoring agent collects disk, CPU, network, and process metrics. You can configure the Monitoring agent also to monitor third-party applications.
Cloud Armor is wrong because it is a service against denial of service and web attacks.
Q 18. Your team has deployed some applications in GKE.
They asked you how they can view a detailed list of the containers with a few commands.
Which is the right statement to use?
A. gcloud container images describe
B. gcloud container images list
C. kubectl container list images
D. kubectl container list images –detail
Correct Answer: A
“gcloud container images describe” gives a detailed description of the containers.
Images are managed by GCP, so the correct command is gcloud not kubectl.
B is wrong because “gcloud container images list” gives a simple list of the images, not a detailed one.
C and D are wrong because it is a task managed by GCP, not by Kubernetes directly.
Q 19. You need to migrate a Python app to GCP. The main problem is that the app may have sudden traffic bursts and you have to scale very quickly.
The main requirements for the app are therefore performance and availability.
Given these requirements, which platform do you choose?
A. Compute Engine with Managed instances group
B. App Engine Standard with automatic scaling
C. App Engine Flex with Automatic scaling
D. Cloud Functions
Correct Answer: B
App Engine Standard Edition scales very quickly and it is faster than the other solutions because the tech environments are already ready to go.
So, if you are sending batches of requests to your services, for example, to a task queue for processing, a large number of instances will be created quickly. We recommend controlling this by rate limiting the number of requests sent per second, if possible. For example, in an App Engine task queue, you can control the rate at which tasks are pushed.
App Engine also scales instances in reverse when request volumes decrease. This scaling helps ensure that all of your application’s current instances are being used to optimal efficiency and cost effectiveness.
A is wrong because Compute Engine is slower because it has to start new instances.
C is wrong because App Engine Flex is slower because it has to start new containers.
D is wrong because Cloud Functions are slower then App Engine and are not suitable for all the applications
Q 20. You have an application that periodically needs to fetch data online and then upload it to BigQuery and Cloud Storage.
You have prepared a bash script to complete the operation.
What do you have to do in order to to authorize the procedure in an automated, simple and scalable way in the VM of the managed instance group on which it is installed?
A. Create the virtual machine with an image or script that provides the necessary roles
B. Set up a service account with the correct privileges and create the instance template of the virtual machine with this service account
C. Write all the proper and needed credentials in the code
D. Create a procedure in App Engine and translate the script in code in order to load the data
Correct Answer B
A and C are wrong for security reasons. You are never advised to expose security information in clear text.
D is wrong because there is no need to code in programming language and, in any case, this not solve out issue.

A service account is a special type of Google account that acts as a non-human user and that can be authenticated and authorized to access resources in GCP.
An instance template is a resource that you can use to create VM instances and managed instance groups.
Instance templates define the machine type, image, identity tags, service accounts and other instance properties.
So, you have to create a service account, grant all the required privileges and then create new virtual machine instances to run as the new service account.
Important: virtual machine instances can use the same service account, but a virtual machine instance can only have one service account identity. If you assign the same service account to multiple virtual machine instances, any subsequent changes you make to the service account will affect instances using the service account.
Q 21. You have an app in App Engine Standard Edition that needs to use Cloud SQL.
Which, among the following, is the best method to authorize all operations safely?
A. Configure the service account
B. Grant all authorizations in the app.yaml file
C. Use JWT
D. Grant all authorizations in the index.yaml file
E. Store the service account key in code
Correct Answer A
B and D are wrong because it is not allowed to store security information or keys in configuration files.
C is wrong because JSON Web Token (JWT) is an open standard that defines a compact and self-contained way for securely transmitting information between parties as a JSON object.
You may sign a JWT token with a service account key and exchange the signed JWT with Google with an oAuth2 procedure.
But it is complicated and useless because you have to authorize your app to use Cloud SQL, not the users.
E is wrong because you can transmit service account key only through secure ways (key store, valts, secured storage); also here it is unnecessarily tricky.
The best way is to configure and use the default service account, automatically created with the app.
A service account is a special type of Google account that acts as a non-human user and that can be authenticated and authorized to access resources in GCP.
You can change the permissions for this service account as needed.
Q 22. What is a columnar Database and which is the GCP Solution?
A. A SQL Database organized in columns instead of rows. Cloud SQL may act as a columnar Database
B. noSQL Database: Cloud Datastore
C. A BigData Solution: Cloud Dataprep
D. A noSQL Database: Cloud BigTable
Correct Answer D
Bigtable is a NoSQL wide-columnar database.
Wide-column and petabyte-scale database store tables that can have a large and variable number of columns, that may be grouped in families.

Cloud Bigtable is a sparsely populated table with 3 dimensions (row, column, time) that can scale to billions of rows and thousands of columns, enabling you to store terabytes or even petabytes of data and to access data at sub-millisecond latencies. A single value in each row is indexed; this value is known as the row key. Cloud Bigtable is ideal for storing very large amounts of single-keyed data with very low latency. It supports high read and write throughput at low latency, and it is an ideal data source for MapReduce operations.
Each row is indexed by a single row key, and columns that are related to one another are typically grouped together into a column family. Each column is identified by a combination of the column family and a column qualifier, which is a unique name within the column family.
Each row/column intersection can contain multiple cells, or versions, at different timestamps, providing a record of how the stored data has been altered over time. Cloud Bigtable tables are sparse; if a cell does not contain any data, it does not take up any space.
Cloud Bigtable scales in direct proportion to the number of machines in your cluster without any bottleneck.
A is wrong because a SQL may not act as a columnar Database, that cannot have joins, secondary indexes and multiple tables.
B is wrong because Cloud Datastore is a document Database, not a columnar Database.
C is wrong because Cloud Dataprep is a completely different product: a data service for visually exploring, cleaning, and preparing structured and unstructured data for analysis, reporting, and machine learning.
Q 23.You are looking for a low-cost database service that supports strong consistency, atomic transaction and serializable isolation.
The data have to be partially structured.
What database and what configuration do you choose?
A. Cloud SQL mySQL with default configuration
B. Cloud SQL Postgres with default configuration
C. Cloud Storage with lifecycle
D. Cloud Datastore with transactional commits
Correct Answer D
Cloud Datastore is a low cost noSQL Managed Database that is partially structured.

Datastore commits are either transactional, meaning they take place in the context of a transaction and the transaction’s set of mutations are either all applied or none are applied, or non-transactional, meaning the set of mutations may not apply as all or none.
Consistency ensures that a user reading data from the database will get the same data no matter which server in a cluster responds to the request.
Datastore can be configured for strong consistency, but IO operations will take longer than if a less strict consistency configuration is used.
Datastore is a good option if your data is unstructured.
Q 24. Which languages ?? you can use with Cloud Spanner?
A. Javascript, Json and GQL
B. Java and GQL
C. Python, Javascript and SQL
D. Python, Javascript, GO, Java, PhP, Ruby and SQL
Correct Answer D
Cloud Spanner is a scalable, enterprise-grade, globally-distributed, and strongly consistent relational built for the cloud that combines the benefits and consistency of traditional databases with non-relational horizontal scale.
Cloud Spanner uses the industry-standard ANSI 2011 SQL for queries and has client libraries for many programming languages.

Q 25. You have been asked to design an app that allows to upload images and documents to Cloud Storage. These files must be processed, classified, and have to remain available for a month. Then they must be archived.
You want to create a simple and functional solution.
Which of the following is the best one?
A. Use Google Cloud Storage Triggers and call a function that executes all the task requested
B. Use Google Cloud Storage Triggers and call a function that classifies files; configure the bucket with a lifecycle rule that changes the storage classes of Objects to Coldline Storage
C. Create a Linux Cron Job in a VM that executes all the task requested
D. Use Cloud Scheduler and setup an Appengine app
Correct Answer B
The best way to archive Storage Objects after a period of time is to use Cloud Storage Object Lifecycle Management.
Everything is automated and done by GCP.
With Storage Triggers you can activate your function on any new file loaded.
A is wrong because a Cloud Function for a batch job (archiving) is useless and not advisable because it is prone to timeout.
C and D are complex and/or expensive: no need of schedulers when automatic triggers are available. In addition, an Appengine app is more expensive than a function and is suitable for complete applications and not single functions.
Conclusion:
This 25 question practice exam builds a good understanding of how a professional Google cloud developer exam would look like. Along with this, you can also explore Google Cloud Free Tier for free practice on the GCP environment. Whizlabs’ free practice exam, video course, and hands-on labs are based on the actual exam patterns. Enroll today for a working understanding of a Google cloud Developer role and also take the exam.
Reference Links:
- https://cloud.google.com/natural-language/docs/
- https://cloud.google.com/dataprep/
- https://cloud.google.com/firestore/
- https://cloud.google.com/certification/cloud-developer
- 25 Free Questions – Certificate of Cloud Security Knowledge V.4 - December 13, 2021
- 25 Free Questions on PL-900 Exam Certification - December 3, 2021
- 50 Free Terraform Certification Exam Questions - December 2, 2021
- 25 Free Questions – GCP Certified Professional Cloud Network Engineer - December 2, 2021
- 25 Free Questions – Microsoft Power BI PL-300 (DA-100) Certification - December 2, 2021
- 25 Free Questions – Google Cloud Developer Certification Exam - November 30, 2021
- 25 Free Questions – Google Cloud Certified Professional Security Engineer - November 30, 2021
- 25 Free Questions – Google Cloud Certified Professional Machine Learning Engineer - November 30, 2021

