

In AWS data engineering, Extract, Transform, and Load (ETL) processes are pivotal, as they allow you to prepare raw data sets for analytical purposes. This blog provides a detailed exploration of data engineering best practices specifically geared toward optimising ETL workflows, enhanced with relevant keywords and concepts for AWS Certified Data Engineer Associate Certification (DEA-C01).
The ETL Process
ETL is the combination of data from multiple sources into a large central repository called a data warehouse. It uses a set of business rules to clean and organise and prepare raw data for such activities as storage, analytics, and machine learning (ML). It provides a consolidated view of data for in-depth analysis and reporting, leading to more accurate data analysis to meet compliance and regulatory standards. The ETL process in AWS works as shown in the diagram and explained below.
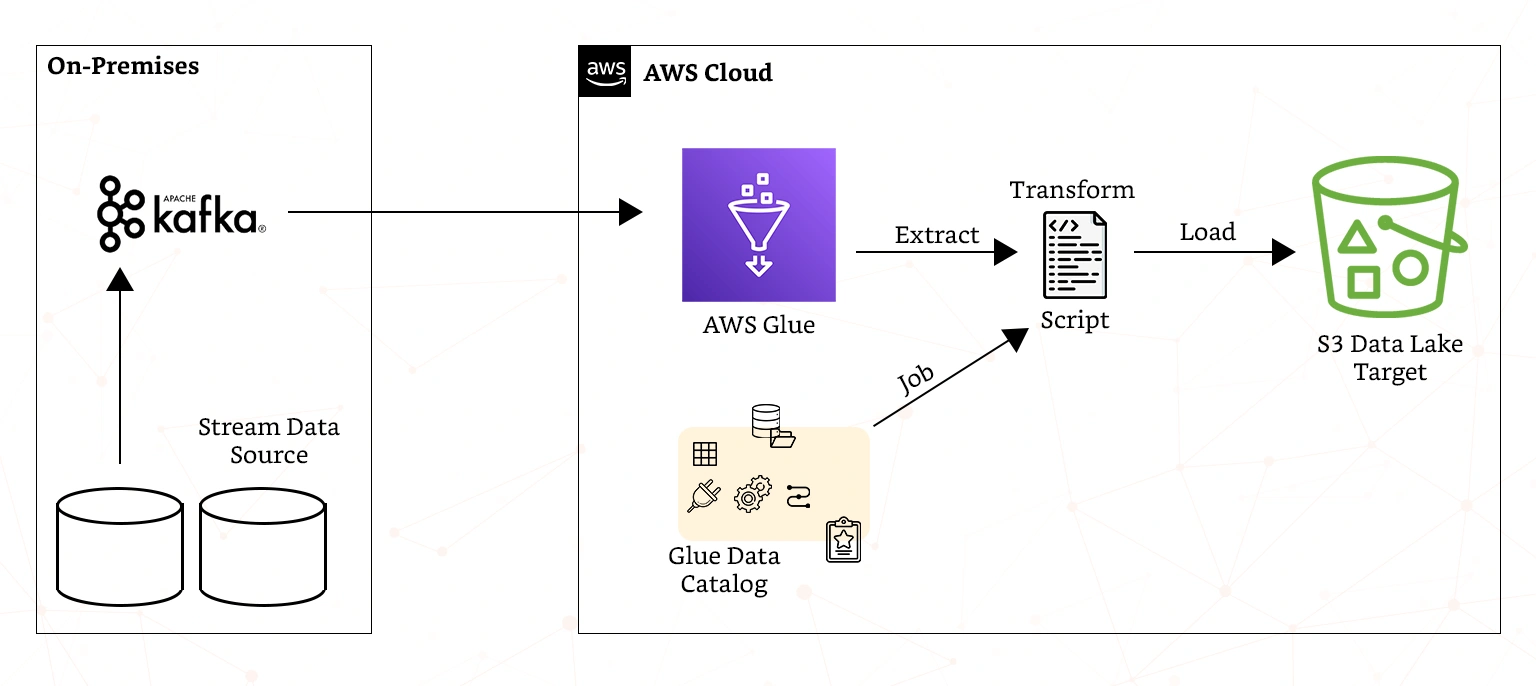
- Data extraction: In data extraction, extract, transform, and load tools extract or copy raw data from its multiple source database and store it in a staging area. A staging area, or landing zone, is an intermediate storage area for temporarily holding the extracted data. This phase also opens AWS connections to source systems, such as databases, APIs, or flat files and extracting the required information.
- Data transformation: ETL tools transform and consolidate the raw data in the staging area in a manner that is suited for analysis. The data transformation phase can involve a variety of types of data changes. The general rule is that before AWS DATA is subjected for analysis, it must be cleaned, transformed, and enriched.
- Data loading: During this stage, ETL tools move the transformed data from the staging area into the target data warehouse. The process of data loading in AWS is usually automated and continuous with the transformed data ingested into an AWS central data repository, such as a data warehouse or data lake.
ETL Best Practices for AWS Data Engineers
AWS Certified Data Engineer Associate Certification (DEA-C01) candidates should follow the following best practices for effective ETL processes;

- Plan before you build: The first step is to develop a clear understanding of its purpose by developing a solid plan. A well-defined plan ensures your workflow meets specific needs. As a candidate for the AWS Certified Data Engineer Associate certification, you need to set clear objectives to help guide design decisions as this will prevent scope creep during the ETL process. You can use AWS data flow diagrams and lineage to visualize how data moves through the ETL process during the planning process.
- Use scalable data processing: When handling big data solutions, it is advisable to use scalable distributed processing frameworks, such as Apache Spark. In addition, use the Concurrency Scaling feature in Amazon Redshift to automatically handle spikes in concurrent read and write query workloads thereby improving performance.
- Maintain clear documentation and lineage: You should also maintain clear documentation and data lineage for transparency and troubleshooting of processed AWS ETL and providing support for audits. Integrate solutions such as OpenMetadata and OpenLineage, to assist in the documentation and visualization of data flows across the AWS ETL pipelines.
- Use bulk loading techniques: The application of bulk loading and partitioning techniques during the load phase assist in minimizing ingestion times in AWL ETL processes and maximize target system performance. Bulk loading techniques offer maximum performance benefits during the load phase, ensuring efficient ingestion of transformed and enriched data into central repositories.
- Ensure data Security and compliance: As a data engineer you should implement robust security measures to protect your data throughout the ETL process. Deploy technologies such as encryption, access controls, and other security features provided by AWS to safeguard your data while complying with data protection regulations and standards especially in those environments governed by data engineering best practices.
- Implement robust real-time monitoring Implement robust monitoring and logging mechanisms are critical for tracking ETL processes’ performance and health, facilitating quick issue resolution. Regular monitoring of AWS ETL pipelines assists in improving data reliability and accuracy.
Best Tools for AWS ETL
It is important to use the right solution functionalities in AWS, as this can lead to efficiency and effectiveness gains. The major capabilities include AWS Glue and Amazon Redshift, as shown in the solution architecture and explained below.
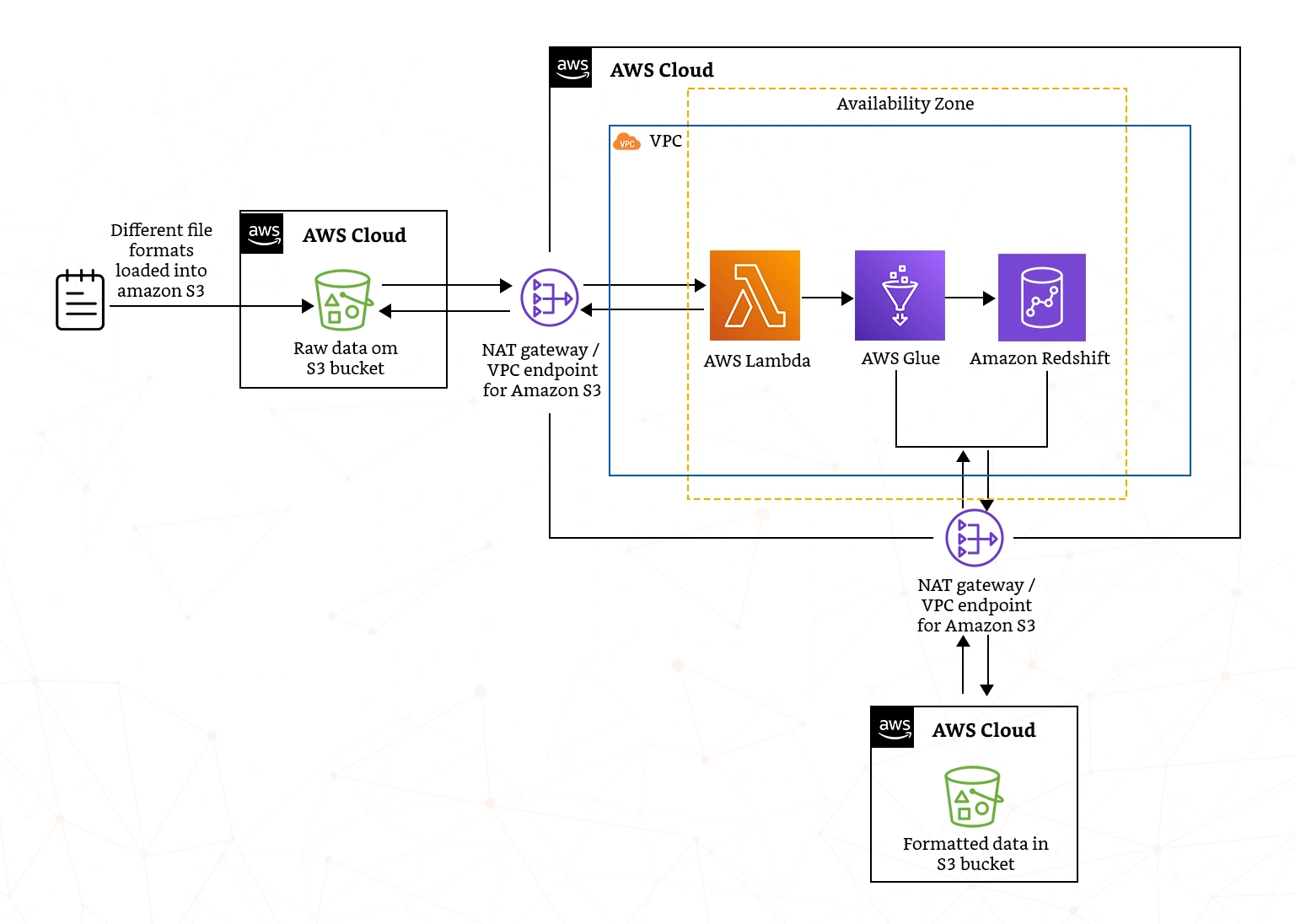
- AWS Glue: This is serverless data integration service that allows you to easily discover, prepare, move, and integrate data from multiple sources for analytics, machine learning, and application development. It allows you to discover and connect to 80+ diverse data stores that can be managed in a centralized data catalog.
- AWS Glue Studio: AWS data engineers can also use AWS Glue Studio to create, run, and monitor ETL pipelines that are used to load data into data lakes. They should also understand the AWS data pipeline vs. AWS Glue proposes that the AWS data pipeline focuses on designing data workflows while AWS Glue focuses more on managing ETL tasks.
- Amazon Redshift: Amazon Redshift is a fast, petabyte-scale AWS data warehouse used to formulate data-driven decisions with relative ease. The functionality also allows data engineers to set up any type of data model and to query data directly from Amazon S3 without loading it into the data warehouse.
- Amazon Managed Workflows for Apache Airflow (MWAA): The MWAA functionality provides a graphical user interface (GUI) functionality that is used to schedule and monitor batch AWS ETL workflows. It consists of a variety of features including retry mechanisms and alerting systems, which can allow manual intervention in. Note also that nowadays AI and ML are also increasingly being integrated to automate and optimize data transformations.
ETL Optimization
There are various ways in which AWS Certified Data Engineer Associate Certification holders can ensure ETL optimization including the following;

- Maximize data quality: The old saying “garbage in, garbage out” also applies to ETL integration. You need to ensure that your feed into your processes is as clean as possible for fast and predictable results. You can deploy automated data quality tools that can help with this task by finding crucial aspects like missing and inconsistent data within your data sets.
- Minimize data input:As a data engineer sitting for the AWS Certified Data Engineer Associate Certification (DEA-C01) exam, you should understand that the fewer data that you have going into the AWS ETL process, the faster and cleaner your results are likely to be. Therefore, you need to remove any unnecessary data as early in the ETL process as possible. This includes cleaning redundant entries in a database before the ETL process starts and not wasting valuable time transforming unneeded data.
- Use Incremental Loading: This process involved the extraction of only that data that has undergone changes since the last extraction. This reduced the load on the source systems and speeded up the ETL process. Using incremental data updates means that when your data sets are updated, you add only the new data into your ETL pipeline. This also saves resources by updating only new or changed records instead of reprocessing the entire data set, allowing you to avoid replacing all the existing data and starting again from scratch.
- Optimize Memory Management: Optimizing memory management is vital when writing AWS Glue ETL jobs. Jobs run on Apache Spark are optimized for in-memory processing. You also need to apply efficient memory utilization processes to ensure smooth operation without unexpected failures. You can also perform data caching, keeping recently used data in memory or on disks where it can be accessed again quickly. This is an easy-to-implement method for speeding AWS ETL processes.
- Leverage Parallel Processing: Parallel processing involves running ETL processes in parallel on multiple partitions.. This is very useful for large datasets, which are typical of AWS data engineering environments as it improves efficiency. Modern parallel processing tools can run multiple tasks simultaneously, improving data processing speeds and reducing bottlenecks. It should be noted that no efficient ETL processes should be serial. Instead, time-to-value is minimised by leveraging parallel processing as much as your AWS infrastructure allows.
- Use Partitioning to Improve Query Performance: Partitioning divides a large dataset into smaller partitions based on specific columns or keys. AWS Glue can perform selective scans on subsets of data, enhancing query performance. You can use the leverage prefix-based partitioning to apply the Amazon Redshift Spectrum’s partition pruning capabilities. This process helps in optimizing performance by partitioning your data while skipping unneeded partitions.
- Use Workload Management to Improve ETL Runtimes: You therefore need to enable automatic WLM maximizes throughput and resource utilization, helping manage distinct workloads. Use automatic WLM to dynamically adjust query concurrency and memory allocation based on the resource requirements of the current AWS thus enhancing the overall performance of the AWS ETL processes.
- Use Automatic Table Optimization (ATO): ATO is a self-tuning functionality in Amazon Redshift that automatically optimizes table designs. It achieves this through various methods including by applying sort, multidimensional data layout sorting, and distribution keys. It continuously observes your queries and uses AI-powered methods to choose the optimal keys that maximize performance for your cluster’s specific workload. ATO helps maintain table performance by automatically optimizing them based on usage patterns, reducing manual intervention required.
- Maximize the benefits of materialized views: Materialized views in Amazon Redshift precompute and store complex query results, significantly improving ETL processes’ performance by reducing recomputation needs. This has the effect of boosting performance for complex or frequently accessed analytical queries such as diligence (BI) dashboards and ELT workloads resulting in low latency for analytical queries.
- Perform multiple steps in a single transaction: Performing multiple steps in a single transaction maintains data consistency and integrity, ensuring all steps are completed successfully before committing changes. As the transformation logic often spans multiple steps minimizing the number of commits in a process is necessary to ensure that each single commitment is performed only after all the transformation logic in the ETL processes has successfully executed.
- Use UNLOAD to extract large result sets: When dealing with large result sets, the UNLOAD command efficiently extracts data being, managing large volumes effectively and ensuring fast and reliable extraction. Because fetching many rows in AWS data extraction is expensive and time-consuming, the UNLOAD command helps in reducing THE elapsed time during the extraction processes therefore enhancing performance.
Conclusion
This blog has revealed the best practices that should be observed by holders of the AWS Certified Data Engineer Associate Certification (DEA-C01) in optimizing the ETL processes. By adhering to best practices and proven principles, you are better placed as an AWS data engineer to ensure that all ETL processes are optimized for performance. This leads to the delivery of accurate results as well as scalable and high-performing data pipelines. The blog is also crucial in assisting your AWS data engineering certification preparation with Hands-on labs and sandboxes. Talk to our experts in case of queries!
- How GCP Cloud Engineers Handle Security & IAM - May 15, 2025
- What Is Amazon Redshift and How Does It Work? - April 28, 2025
- What Is the Role of AWS Lambda in AI Model Deployment? - April 2, 2025
- What Are ETL Best Practices for AWS Data Engineers - March 17, 2025
- How to Create Secure User Authentication with AWS Cognito for Cloud Applications - September 30, 2024
- 2024 Roadmap to AWS Security Specialty Certification Success - August 16, 2024
- Top 25 AWS Full Stack Developer Interview Questions & Answers - August 14, 2024
- AWS Machine Learning Specialty vs Google ML Engineer – Difference - August 9, 2024
