

This blog highlights how to build a serverless architecture for data stream processing in real-time and also you can learn how to connect AWS Lambda to Amazon Kinesis Data Stream. Real-time data means that data is processed as soon as it is generated, ingested, analyzed, and utilized. Such data is useful in many functions that require real-time action, for example, decision-making, fraud detection, customer targeting, predictive analysis, and others.
For developers, who wish to develop their skills in cloud Computing then knowing AWS Lambda and Amazon Kinesis is important. If you want to learn how to set up a serverless architecture using Lambda and Kinesis Streams then AWS Certified Developer Associate Certification plays a crucial role here. This certification ensures you have the skills needed to deploy and manage cloud-native applications efficiently using AWS services.
Note to the reader: In this blog, Kinesis Data Streams and Kinesis Streams are used interchangeably.
AWS Lambda overview
AWS Lambda is a serverless event-driven compute service that allows you to run codes, also known as functions, without provisioning or managing servers. Lambda integrates with many AWS services such as Kinesis, Amazon S3, Amazon DynamoDB, and others, making it easy to deploy in different customer use cases. Many of these services produce events, and they can act as event sources for Lambda.
Unlike traditional servers, Lambda functions do not run constantly; they run only when invoked by an event such as data arriving in Kinesis Streams. Lambda functions are short-lived and can time out after 15 minutes. Due to this design, Lambda takes less startup time for short-lived, event-triggered functions, making it ideal for real-time processing use cases.
In addition, As a serverless service, Lambda not only lowers server resource management but also enhances performance with automatic scaling.
Amazon Kinesis Data Streams
Amazon Kinesis Data Streams is a cloud service that captures and processes streaming data in what we can describe as an “on the go” manner regardless of the amount of streams. Kinesis Streams is highly scalable, and you can configure thousands of producers to send data. For instance, the sources of data might include website clickstreams, IoT devices, mobile apps, social media feeds, log files, and so on. Kinesis Streams continuously capture gigabytes of data per second and make it available in milliseconds. What is more, it works with Lambda and other Kinesis and AWS services and enables you to design a channel for effective real-time data processing and analysis. Kinesis Streams is one of the services under the Amazon Kinesis umbrella.
The Kinesis Family of Products
The four services in the Kinesis framework— Kinesis Streams, Kinesis Data Firehose, Kinesis Data Analytics, and Kinesis Video Streams— have real-time streaming at their core and they complement each other. Based on your requirements, you can mix and match these services to gather more insights from the data.
The following information will help to understand how these services layer each other:
- Kinesis Data Firehose: After Kinesis Streams ingests the data, you might need to load this data into AWS data stores. Firehose can transform and load this data to the destination data stores. For more information, see AWS Kinesis Data Streams vs AWS Kinesis Data Firehose.
- Kinesis Data Analytics: You might wonder “What should I do with my data?” Without analysis, data has no meaning or context. You can integrate Kinesis Data Analytics with Kinesis Streams to run SQL queries and apply real-time analytics to the streaming data, generating patterns and actionable insights.
- Kinesis Video Streams: While Kinesis Streams captures general data streams, Kinesis Video Streams can stream video from almost any video device you can think of devices such as security cameras, smartphone video, drones, RADARs, LIDARs, satellites, and more. You can club both these streaming services in scenarios where you need to handle different types of streaming data.
Connect AWS Lambda to Amazon Kinesis Data Stream
With virtually no server administration, you can create a highly scalable, real-time data processing pipeline using Lambda-Kinesis Streams integration. The following points illustrate how the Lambda-Kinesis Stream combo can help build a robust, real-time data processing system:
- High throughput and data retention: Kinesis Streams offers high throughput for data ingestion, processing, and scaling. It provides configurable retention periods up to a maximum of seven days.
- Zero data loss in streaming pipelines: Kinesis Streams keeps up with the flow of new data and streams it as is without zero data loss in the transmission process.
- Event-driven data handling: Lambda functions are triggered automatically by new data in the Kinesis stream. This enables real-time processing and immediate reactions to data changes.
- Scalability: Lambda scales automatically with the volume of data in the Kinesis stream. As data throughput increases, Lambda handles scaling without manual intervention, ensuring efficient processing of large data volumes.
- Integration with Other AWS Services: Lambda integrates with many AWS services, such as Amazon S3, DynamoDB, and SNS, which simplifies workflows and data pipelines.
Points to know before integration
Here are some concepts and information to keep in mind while connecting Lambda to Kinesis Data Streams for stream processing:
Producers and consumers: Producers send data to Kinesis Streams. Producers can be Web applications, IoT devices, Social Media platforms, mobile apps, and thousands of other sources. Consumers retrieve data from Kinesis Data Streams. Examples include Lambda, EC2 instances, Kinesis Data Analytics, and so on.
Sending data to Amazon Kinesis Data Stream: Producers can use the following options to send data to Kinesis Data Streams:
-
- Write code using the AWS SDKs.
- Use Amazon Kinesis Agent
- Use Amazon Kinesis Producer Library (KPL) and Kinesis Data Streams API.
Shards: Kinesis streams are partitioned in shards— a uniquely identified sequence of data records in a stream. Each shard can handle up to 5 read transactions per second, with a maximum read rate of 2 MB per second. For writes, each shard can process up to 1,000 records per second, with a maximum write rate of 1 MB per second (including partition keys).
- Shard records: A record is the unit of data stored in an Amazon Kinesis Data Stream. Each data record has a Partition Key, Sequence Number, and Data Blob. Lambda uses this information to ensure records are processed in order (via sequence numbers), group data (via partition keys), and decode and act upon the payload (from the data blob).
- Lambda batch size and batch window: You can use batch size and batch window to control how often Lambda is triggered. The batch window allows you to set the maximum amount of time in seconds (maximum 300 seconds or 5 mins), that Lambda spends gathering records before invoking the function. A batch size is the number of messages or records that are included in a single Lambda invocation. When using Lambda as a consumer for Kinesis Streams, the default batch size is 100 records per invocation. You can customize this batch size to a value between 1 and 10,000 records, depending on your workload.
- Capacity modes: It checks how the data stream capacity is managed and charged. The total data capacity of your stream depends on the number of shards you have, and the stream’s overall capacity is the combined capacity of all its shards. Kinesis Data Streams offers two modes:
- On-demand: automatically scales the capacity in response to varying data traffic. You are charged per gigabyte of data written, read, and stored in the stream, in a pay-per-throughput fashion.
- Provisioned: requires you to specify the number of shards manually while creating the Kinesis Streams. You can increase or decrease the number of shards in a data stream as needed, and you pay for the number of shards at an hourly rate.
Monitoring and Securing Lambda Connection with Data Streams
To ensure smooth data flow, system performance, and protection of sensitive information you must secure and monitor the Lambda-Kinesis Streams integration. Security measures include fine-grained access control and encryption of data at rest and in transit. Monitoring involves tracking key performance metrics such as function execution duration, invocation rates, error rates, and throttling. The following AWS services help you monitor and secure Lambda integration with Data Stream:
- Identity and Access Management (IAM) Roles for security: you can use IAM with Kinesis Data Streams to give or restrict permissions to users in your organization from performing a task using specific Kinesis Data Streams API actions or using specific AWS resources.
For the Lambda execution role to read from the Kinesis Streams and write to other services (e.g., CloudWatch Logs, S3, or DynamoDB), you must ensure that it’s the correct IAM permissions.
- AWS Key Management Service (KMS) for encryption: By default, Lambda provides server-side encryption at rest with an AWS-managed KMS key. You can use a customer-managed key for complete control of the key. When you use environment variables, you can enable console encryption helpers to use client-side encryption to protect the environment variables in transit.
- Kinesis Data Streams uses the server-side encryption feature to automatically encrypt data as it enters and leaves the service. If you use this feature, you must specify an AWS KMS customer master key (CMK).
- Amazon CloudWatch for monitoring: Kinesis Stream and Lambda are integrated with CloudWatch. Kinesis Data Streams sends Amazon CloudWatch custom metrics with detailed monitoring for each stream. Lambda automatically monitors Lambda functions and reports metrics through Amazon CloudWatch. Further, Lambda captures logs for all requests that a function handles and sends them to Amazon CloudWatch Logs. These logs and metrics help you to monitor health and performance and troubleshoot issues quickly.
Integrate Lambda with Kinesis Data Streams for Stream Processing
In this section, we will connect Lambda to Kinesis Streams to create a stream processing pipeline.
Summary of end-to-end deployment steps
1. Set up Kinesis Data Streams
-
- Create a Kinesis Data Stream to data from various sources.
- Add encryption to protect sensitive data as it flows through the system.
2. Integrate data sources (producers)
-
- Configure data sources to send data to Kinesis Data Streams.
3. Create a Lambda Function:
- Create an AWS Lambda function to process incoming data from the Kinesis Data Streams.
- Apply required permissions and policies.
4. Configure data processing:
-
- Set up the Lambda function to be triggered by records in the Kinesis Data Streams.
- Define processing rules, filtering, and formatting requirements.
Procedures
Kinesis-side configuration
Step 1: Create a data stream
1. From the Kinesis console, click “Create data stream”

2. Add a data stream name
3. Under Data stream capacity, specify the capacity mode and other details and click “Create Data stream”.
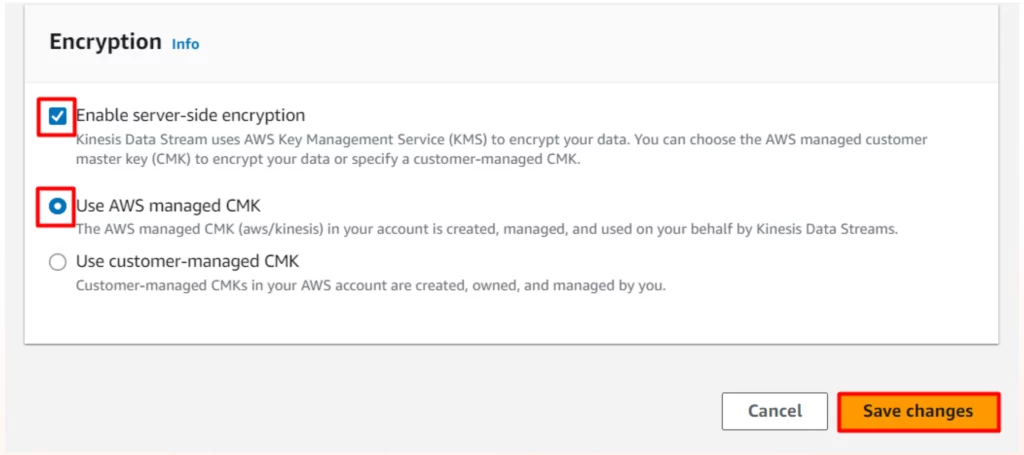
Step 1: Add encryption to Kinesis Streams
- Select the stream you created and click Encryption. Select the following options and click Save Changes.
Lambda-side configuration
This section describes the Lambda-side configuration that connects AWS Lambda to Amazon Kinesis Data Streams.
Step 1: Create a Lambda function
1. Go to the AWS Lambda console and create a function

2. Select the Author from scratch.
3. In the Basic information pane, enter a Function name.
4. From the Runtime drop-down menu, select an option.
5. Select the required architecture and click the Create function.
Step 2: Add permissions to the Lambda function to access Kinesis Data Streams
1. On the function page, click Configurations>Permissions.
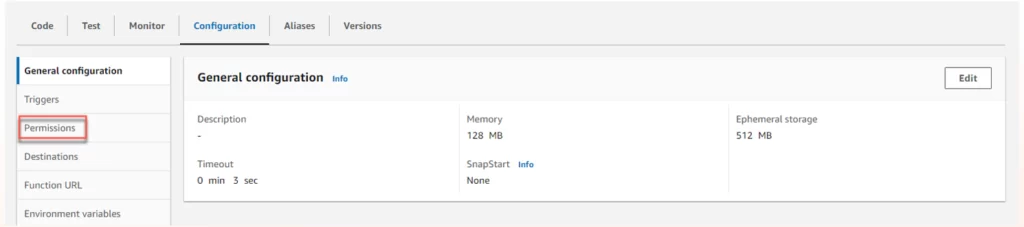
2. Click the Lambda role for the function you created. The Identity and Access Management (IAM) console opens. This role has a basic execution policy.
3. Next, click Add Permissions. From the drop-down menu, select Attach policies.
4. Search for the required policies. Select them and click Attach policies.
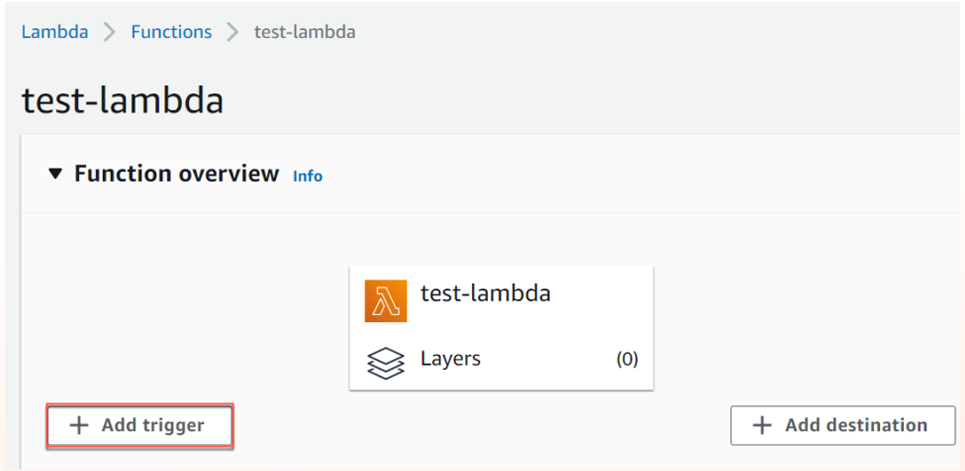
Step 3: Add Kinesis as a trigger to Lambda for real-time processing of streaming data
1. From the Lambda function page, click Add trigger. The Trigger configuration window opens.
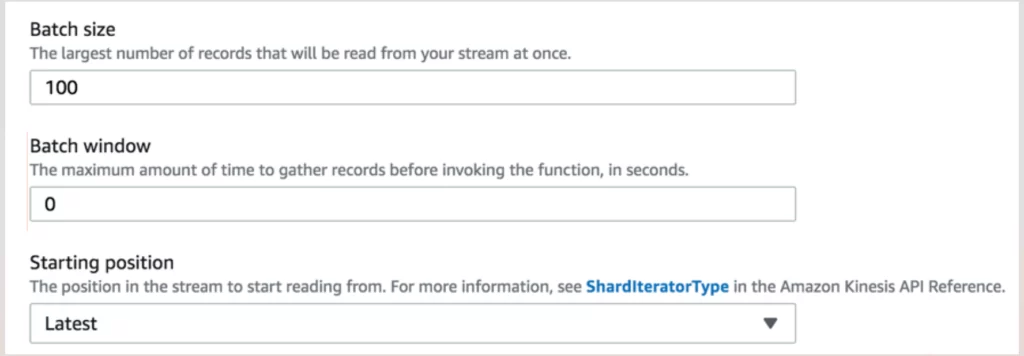
2. In Select a source, search for Kinesis and fill out the options in the Trigger Configuration pane.
- Kinesis stream: Select the Kinesis stream you’ve created previously.
- Check the Activate trigger.
- Add batch size, batch, window, and starting position, and then click Add.
Step 4: Add code to the Lambda function
1. On the function page, click Code.
2. Add the Lambda code and click Deploy to save the changes and deploy.
In addition to the steps illustrated in this section, you must configure data producers to Kinesis Data Streams.
Conclusion
As real-time data processing becomes all pervasive and encompassing in the business world, your ability to professional data pipelines capable of processing big data at scale becomes a decisive skill. The best way to build the required skills is by taking specialized courses and hands-on labs. These courses typically cover the essential steps of building, testing, and deploying data pipelines, as well as the best practices for ensuring scalability and efficiency. Sign up for the Whizlabs guided lab Build a real-time data streaming system with Amazon Kinesis Data Streams and sharpen your skills. For additional hands-on experience of the services, check our AWS hands-on labs and AWS sandboxes.
- Mitigating DDoS Attacks on AWS with Security Specialty Certification Knowledge - October 17, 2024
- How to Connect AWS Lambda to Amazon Kinesis Data Stream? - October 3, 2024
- Deploying and Optimizing Machine Learning Models on AWS - September 3, 2024
- How to Pass Microsoft Azure Administrator Associate Exam on Your First Attempt - August 29, 2024
