

Cloud Dataproc and Cloud Dataflow are cloud-based data processing services released by Google Cloud Platform.
The prime difference between Cloud Dataproc vs Cloud Dataflow is that Dataproc is primarily created for batch processing of large datasets with the help of Hadoop and Spark, while Dataflow is designed for larger dataset batch processing in real-time with varied data processing techniques such as Apache Beam.
In this blog post, we are going to make a comparative study between Cloud Dataproc vs Cloud Dataflow in detail.
Let’s dig in!
Cloud Dataproc vs Cloud Dataflow: Key Definitions
Cloud Dataproc
Dataproc service is a managed Spark and Hadoop service that helps to do tasks such as batch processing, querying, and streaming.
Presto, Apache Spark, Apache Flink, and other open-source frameworks and tools are scaled by the Dataproc service. This service is also used for safe data science with Google Cloud, ETL, and data lake modernization at a fraction of the cost.
Additionally, Dataproc helps to modernize data processing for open-source software. That is to say, you can accelerate your data and analytics processing by revolving custom environments on demand.
It offers integrated security, autoscaling, cluster deletion, per-second pricing, and ways to reduce expenses and security threats.
Finally, it features advanced security, legal compliance, and governance to manage user authorization and authentication with Personal Cluster Authentication or current Apache Ranger policies and Kerberos.
The unique features of Cloud Dataproc such as:
- Managed and Automated Open-Source Software
- Containerizing Apache Spark Jobs with Kubernetes
- Enterprise Security with Google Cloud
- Open Source with Google Cloud Integration
- Resizable Clusters
- Autoscaling Clusters
- Cloud Integrated
- Versioning
- Highly Available
- Cluster Scheduled Deletion
- Automatic or Manual Configuration
- Developer Tools & Initialization Actions
- Workflow Templates
When to use Dataproc?
You can consider using the dataproc in the following scenarios:
- If you are considering shifting to the cloud after making a sizable on-premises investment in Apache Spark or Hadoop
- If you are investigating a hybrid cloud and require mobility across a private/multi-cloud environment
- If Spark is the main machine learning tool and platform in the present environment
- If the code requires distributed computing and depends on any bespoke packages
Also Read : What is google cloud dataproc?
Google Cloud Dataflow
Google Cloud Platform offers a completely managed data processing solution called Google Cloud Dataflow. For batch and stream processing jobs, it makes you create, implement, and oversee data processing pipelines.
Both batch processing—which processes data in fixed-size chunks—and stream processing—which processes data as it comes in—are supported by this integrated programming model.
Features of Google Cloud Dataflow such as:
- Autoscaling and Dynamic Work Rebalancing
- Flexible Scheduling and Pricing for Batch Processing
- Real-Time AI Patterns
- Right Fitting
- Streaming Engine
- Horizontal Autoscaling
- Vertical Autoscaling
- Dataflow Shuffle
- Dataflow SQL
- Dataflow Templates
- Inline Monitoring
- Dataflow VPC Service Controls
- Private IPs
Read More: What is google cloud dataflow?
Cloud Dataproc vs Cloud Dataflow: Pricing
Cloud Dataproc pricing
The dataproc pricing depends on the dataproc cluster size and running time duration. The cluster size varies depending on the aggregated number of virtualized clusters over the entire cluster, including master and worker nodes.
Furthermore, cluster duration refers to the length of time taken between the creation of a cluster and cluster deletion.
The dataproc pricing can be calculated by:
$0.010 * # of vCPUs * hourly duration
The dataproc clusters need to be tuned in one-second time intervals, dataproc is paid by second and subject to one-minute billing. In addition, the utilization can be represented in fractional hours so that the second-by-second usage can be altered according to the hourly rates.
Cloud Dataflow pricing
GCP Dataflow furnishes flexible pricing based on the resources utilized by data processing jobs. However, the Dataflow service usage is charged in per-second increments, on a per-job basis.
In the data flow, the pricing rate is dependent on an hourly basis. The service usage of the dataflow will be charged in increments per second on a job basis. Moreover, the usage can be expressed in terms of hours for the hourly pricing to the second usage.
Each Dataflow job requires at least one Dataflow worker, and the Dataflow service provides two distinct worker types: batch and streaming, each with separate service charges.
Dataflow workers incur charges for the following resources, billed on a per-second basis:
- vCPU (Virtual Central Processing Unit): The computational power of the worker is measured in vCPUs, and charges are based on the duration of usage.
- Memory: Memory consumption by Dataflow workers is also billed on a per-second basis, reflecting the amount used during the job execution.
- Storage – Persistent Disk: Persistent Disk storage utilized by the workers is a chargeable resource, with costs calculated per second.
- GPU (optional): If GPUs are employed in the Dataflow job for enhanced processing capabilities, charges for GPU usage are applicable.
In addition to these worker resource charges, the Dataflow service incorporates a shuffle implementation that takes place on worker virtual machines.
This approach ensures that the costs associated with Data Shuffle operations are accounted for about the specific requirements of each Dataflow job.
Use cases of Cloud Dataproc and Cloud Dataflow
Cloud Dataproc Use Cases
Enterprises are increasingly transitioning their on-premises Apache Hadoop and Spark clusters to Google Cloud’s Dataproc for efficient cost management and harnessing the benefits of elastic scalability. Dataproc provides a fully managed, purpose-built cluster with autoscaling capabilities, ensuring optimal support for various data and analytics processing tasks.
Moreover, Dataproc facilitates the creation of an ideal data science environment. Users can configure a purpose-built Dataproc cluster, integrating open-source software with Google Cloud AI services and GPUs to accelerate machine learning and AI development.
Supported software includes Apache Spark, NVIDIA RAPIDS, and Jupyter Notebooks, offering a versatile and powerful platform for data science initiatives.
Cloud Dataflow Use Cases
GCP Dataflow stands out as a robust choice for constructing and executing data pipelines across a range of applications due to its attributes of Scalability, Flexibility, and Performance.
Here are some key use cases that highlight its capabilities:
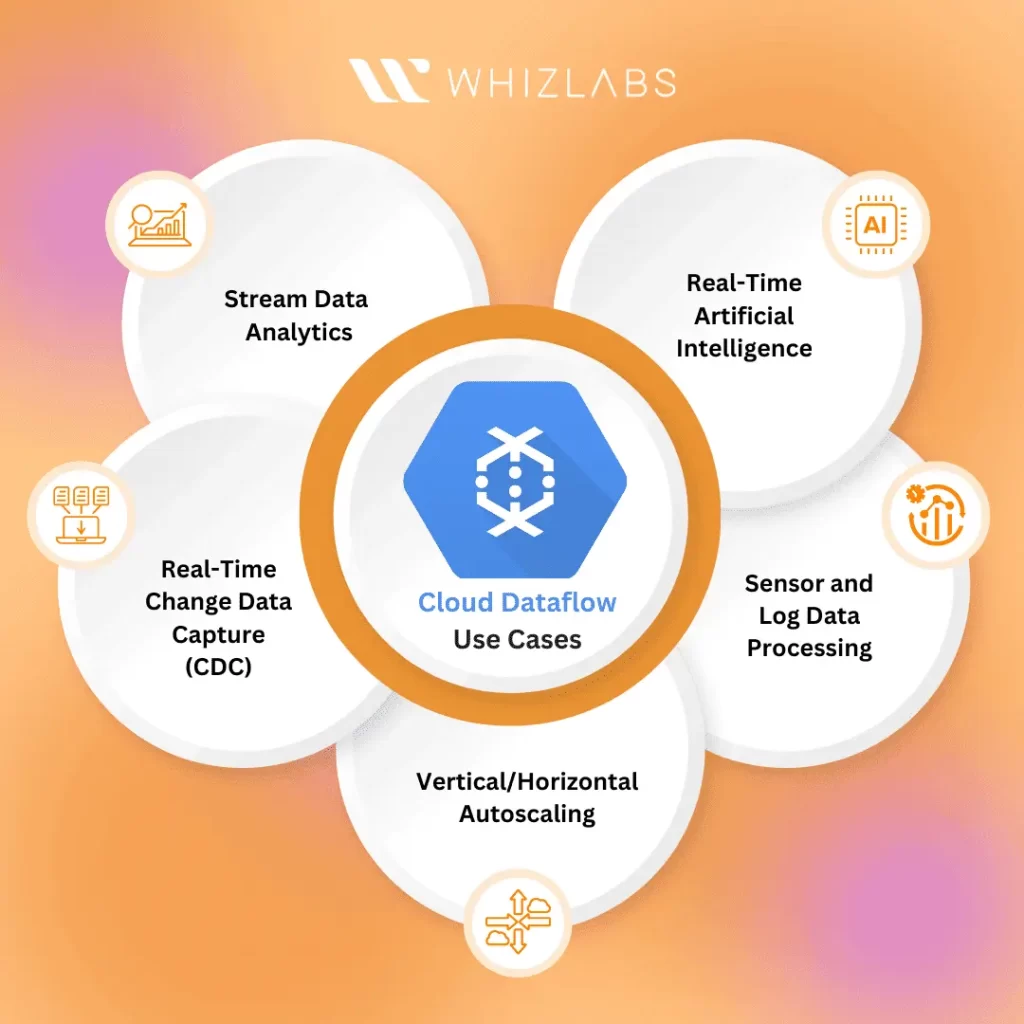
- Stream Data Analytics: GCP Dataflow utilizes Pub/Sub, and BigQuery, offering an effective solution for organizing and accessing meaningful data in real-time. This streamlined provisioning approach simplifies the complexity of processing streaming data, providing data scientists and analysts quick access to real-time insights.
- Real-Time Artificial Intelligence: Google Cloud DataFlow seamlessly integrates with TFX and Vertex AI, facilitating streaming events to support predictive analytics, real-time personalization, and fraud detection. Specific sub-use cases, such as anomaly detection, pattern recognition, and predictive forecasting, can benefit from DataFlow’s support of the Apache Beam programming model and its role as a distributed data processing engine.
- Sensor and Log Data Processing: Cloud Dataflow’s scalability and integration capabilities enable businesses to gain insights and monitor data from a global network of IoT devices. This is particularly useful for employing cognitive IoT capabilities, allowing users to connect, store, and analyze data both on Google Cloud and edge devices.
- Vertical/Horizontal Autoscaling: Cloud Dataflow’s adaptive worker scaling, combined with vertical autoscaling in the Dataflow Prime service, optimizes computational capacity based on demand. Horizontal autoscaling dynamically adjusts the number of worker instances during runtime, ensuring efficient resource utilization. This automatic scaling mechanism enhances pipeline efficiency by spinning up or shutting down workers as needed.
- Real-Time Change Data Capture (CDC): Data professionals leverage the Dataflow service for reliable and low-latency synchronization and replication of data across diverse sources. By integrating with Google Datastream, the Dataflow template library facilitates seamless data replication from Cloud Storage into platforms like Google BigQuery, PostgreSQL, or Cloud Spanner.
Cloud Dataproc vs Cloud Dataflow: Know the Differences
| Service | Description | Features | Programming Languages | Pricing | Supported Data Sources |
| Dataproc | Fully managed Hadoop and Spark service |
|
Java, Python, Scala, R | Based on cluster size and duration | HDFS, Google Cloud Storage, Bigtable |
| Dataflow | Serverless service based on Apache Beam |
|
Python, Java, Go | Based on the number of virtual machines and the duration of their usage | Google Cloud Storage, Google BigQuery, Apache Kafka |
Cloud Dataproc vs Cloud Dataflow: Which one to choose?
Cloud Dataflow and Dataproc are distinct services within the Google Cloud Platform, both designed for data processing. The decision between the two relies not only on their differences but also on specific organizational needs.
You can opt for Dataproc if there’s a prior dependency on Spark/Hadoop from previous roles, while Dataflow is preferable if the team possesses substantial Apache Beam expertise, offering time and cost savings.
A hands-on DevOps approach aligns with Dataproc, whereas a serverless approach is favored with Dataflow. If leveraging Google’s premium data processing and distribution services without delving deep into parallel processing is the goal, Dataflow is the suitable choice.
Cloud Dataproc excels in handling substantial data volumes in batch mode, whereas Cloud Dataflow is tailored for real-time data processing, converting it into the desired format for analysis. The selection between these services hinges on the organization’s precise data processing requirements.
Similarities between Dataproc and Dataflow
A few commonalities exist between Dataproc and Dataflow as follows:
- Both are Google Cloud products
- Every pricing point is included in the same range; for example, new users can receive $300 in free credits on Dataproc and Dataflow for the first ninety days of their trial.
- Both items have comparable support
- They’re all classified as big data dissemination and processing.
FAQs
What are the alternatives to GCP Dataflow and Google Cloud Dataproc?
- Apache Spark
- Kafka
- Hadoop
- Akutan
- Apache Beam
How do we reduce dataflow costs in GCP?
Cost savings are achieved through parallelization within a single worker, as it allows the processing of a greater number of elements. By enhancing the efficiency of a single worker in handling more elements, Dataflow requires a reduced number of workers for your job.
What makes GCP dataflow preferable to datasets?
Dataflow is strongly advised in situations when you frequently reuse the same tables across several files. This is because dataflow will give you an ETL (Extract-Transform-Load) component that can be reused.
Is dataflow an ETL tool?
Yes, Dataflow is a reliable serverless solution designed to meet your Extract-Transform-Load (ETL) requirements, offered by Google Cloud Platform (GCP).
Conclusion
I hope this blog distinguished between GCP Dataproc and Dataflow, highlighting their comparable capabilities in data processing, cleaning, ETL, and distribution.
Each platform is adept at addressing specific requirements. If your project relies on Hadoop/Apache services, Dataproc emerges as the optimal choice.
Even in the absence of such dependencies, if you prefer a hands-on approach to big data processing, Dataproc remains a viable option.
However, for those seeking to leverage Google’s premium Cloud data processing and distribution services without delving into intricate details, Dataflow presents an ideal solution.
- Study Guide DP-600 : Implementing Analytics Solutions Using Microsoft Fabric Certification Exam - June 14, 2024
- Top 15 Azure Data Factory Interview Questions & Answers - June 5, 2024
- Top Data Science Interview Questions and Answers (2024) - May 30, 2024
- What is a Kubernetes Cluster? - May 22, 2024
- What are the Roles and Responsibilities of an AWS Sysops Administrator? - March 28, 2024
- How to Create Azure Network Security Groups? - March 15, 2024
- What is the difference between Cloud Dataproc and Cloud Dataflow? - March 13, 2024
- What are the benefits of having an AWS SysOps Administrator certification? - March 1, 2024