
Azure Data Factory empowers businesses to orchestrate and automate their data pipelines seamlessly within the Microsoft Azure ecosystem.
In this blog post, we will look into what Azure Data Factory (ADF) is, exploring its fundamental concepts, practical applications, and best practices.
Whether you’re a seasoned data engineer, a business analyst, or an aspiring data professional, this article aims to provide a comprehensive understanding of Azure Data Factory, enabling you to harness its full potential in driving data-driven success.
What is Azure Data Factory (ADF)?
Azure Data Factory is a cloud-based data integration service provided by Microsoft Azure. Its primary purpose is to enable users to create, schedule, and manage data pipelines for moving and transforming data across various sources and destinations.
Essentially, Azure Data Factory acts as an orchestrator, allowing organizations to ingest data from diverse sources, transform it as needed, and load it into target systems for storage, analytics, and reporting purposes.
Its code-free design and visual interface make it accessible to a broad range of users, while its underlying scalability and data processing power cater to complex enterprise data integration needs.
At its core, Azure Data Factory facilitates the extraction, transformation, and loading (ETL) or extraction, loading, and transformation (ELT) processes, commonly used in data warehousing and analytics scenarios. It supports both batch and real-time data processing, catering to a wide range of data integration requirements.
To know the Azure data factory pricing, check the Azure Data Factory documentation.
What are the key components of Azure Data Factory?
Azure Data Factory comprises several key components that work together to facilitate data integration, transformation, and coordination processes. Understanding these components is essential for designing and managing data pipelines effectively.
Here are the key components of Azure Data Factory:
- Data Flows: Data flows define the data transformation logic within Azure Data Factory. They consist of activities that perform various operations on the data such as filtering, joining, aggregating, and mapping columns. Data flows can be designed using a visual drag-and-drop interface or through code using Mapping Data Flow.
- Datasets: Datasets represent the data structures within Azure Data Factory. They define the structure and schema of the data being ingested, transformed, or outputted by activities in the data pipelines. Datasets can reference data stored in various sources such as files, databases, tables, or external services.
- Linked Services: Linked services establish connections to external data sources and destinations within Azure Data Factory. They provide the necessary configuration settings and credentials to access data stored in different platforms or services, including Azure services, on-premises systems, and third-party cloud providers.
- Pipelines: Azure Data Factory pipeline serves as the coordinator of data movement and transformation processes. They consist of activities arranged in a sequence or parallel structure to define the workflow of the data processing tasks. Pipelines can include activities for data ingestion, transformation, staging, and loading into target systems.
- Triggers: Triggers define the execution schedule or event-based triggers for running pipelines in Azure Data Factory. They enable automated and scheduled execution of data integration workflows based on predefined conditions, such as a specific time, recurrence, data availability, or external events.
- Integration Runtimes: Integration runtimes provide the compute infrastructure for executing data movement and transformation activities within Azure Data Factory. They manage the resources needed to connect to data sources, execute data processing tasks, and interact with external services securely. Integration runtimes support different deployment models, including Azure, self-hosted, and Azure-SSIS (SQL Server Integration Services).
- Data Flow Debug Mode: This component enables developers to debug data flows within Azure Data Factory, allowing them to validate the transformation logic, troubleshoot issues, and optimize performance. The debug mode provides real-time monitoring of data processing activities and intermediate data outputs during pipeline execution.
How does an Azure Data Factory work?
Azure Data Factory encompasses a network of interconnected systems, offering a comprehensive end-to-end platform tailored for data engineers.It operates through a streamlined process encompassing several key stages: Connect and Ingest, Transform and Enrich, Deploy, and Monitor.
Ingest Data
- Leverage numerous built-in connectors (over 100 according to the image) to access data from various cloud and on-premise sources. This includes databases, SaaS applications, and data warehouses.
Design Data Pipelines
- ADF offers a code-free user interface for designing data pipelines. This graphical interface allows users to construct pipelines by dragging and dropping elements.
- Pipelines, also known as workflows in ADF, are essentially a sequence of activities that define how data should flow through the system. ADF supports building both ETL and ELT workflows.
- ETL (Extract, Transform, Load) involves extracting data from a source, transforming it as needed, and then loading it into a destination data store.
- ELT (Extract, Load, Transform) is similar to ETL, but the transformation step occurs after the data is loaded into the destination.
Data Transformation
- ADF provides a visual interface for designing data transformations. This interface uses drag-and-drop functionality to build data flows that specify how data should be transformed.
- Transformations can include things like filtering, sorting, aggregating, and joining data from multiple sources.
- ADF also supports using code-based transformations for more complex scenarios.
Schedule and Monitor
- Once your data pipelines are designed, you can schedule them to run on a regular basis. ADF supports various scheduling options, including hourly, daily, weekly, and even event-based triggers.
- ADF also provides monitoring capabilities that allow you to track the progress of your pipelines and identify any errors that may occur.
Real-World Use Cases for Azure Data Factory
Azure Data Factory (ADF) offers a versatile set of functionalities that cater to various data management needs.
Here’s a detailed breakdown of its key use cases:
1. Data Warehousing and Business Intelligence (BI):
Challenge: Businesses often have data scattered across diverse sources like databases, applications, and flat files. This fragmented data makes it difficult to build and maintain data warehouses for BI reporting and analytics.
Solution with ADF: ADF excels at ingesting data from these disparate sources. It can orchestrate data pipelines that extract data, transform it as needed (cleansing, filtering, joining), and load it into a central data warehouse like Azure Synapse Analytics. This streamlines data preparation for BI tools, enabling users to generate insightful reports and dashboards.
2. Data Lake Management and Analytics:
Challenge: Data lakes are repositories for storing vast amounts of raw, unstructured, and semi-structured data. However, managing and analyzing this data requires efficient pipelines to process and transform it into usable formats.
Solution with ADF: ADF integrates seamlessly with Azure Data Lake Storage. It can create pipelines that ingest data from various sources and land it in the data lake. Additionally, ADF’s data flow capabilities allow for data cleansing, filtering, and transformation before feeding the data into big data analytics tools like Spark or machine learning models.
3. Cloud Migration and Data Integration:
Challenge: Migrating data to the cloud can be complex, especially when dealing with legacy on-premises data stores. Businesses need a way to seamlessly integrate cloud and on-premise data sources.
Solution with ADF: ADF acts as a bridge between cloud and on-premise environments. It offers a wide range of connectors that enable data extraction from on-premises databases, file systems, and applications. ADF pipelines can then orchestrate the transfer and transformation of this data to cloud-based data stores like Azure SQL Database or Azure Blob Storage. This facilitates a smooth cloud migration journey and allows for continued analysis of combined datasets.
4. Real-Time Data Processing and Event Streaming:
Challenge: Businesses increasingly need to handle real-time data streams generated by sensors, social media feeds, and application logs. This real-time data holds immense value for operational insights and customer behavior analysis.
Solution with ADF: ADF can integrate with Azure Event Hubs or other real-time data streaming services. Pipelines built in ADF can trigger on new data arrivals and process it in near real-time. This allows for immediate actions and reactions based on real-time data insights. For instance, fraud detection systems can leverage ADF pipelines to analyze incoming transactions and identify suspicious activities instantly.
Creating Your First Azure Data Factory (ADF) Pipeline
Azure Data Factory (ADF) simplifies data movement and transformation through its visual interface and built-in functionalities. Here’s a step-by-step guide to creating your first ADF pipeline:
Prerequisites
- An Azure subscription: Sign up for a free trial if you don’t have one already (https://azure.microsoft.com/en-us/free)
- Access to the Azure portal: You’ll be using the Azure portal to create and manage your ADF resources.
Here’s a step-by-step guide on how to create Azure Data Factory (ADF) Pipeline:
1. Create an Azure Data Factory
-
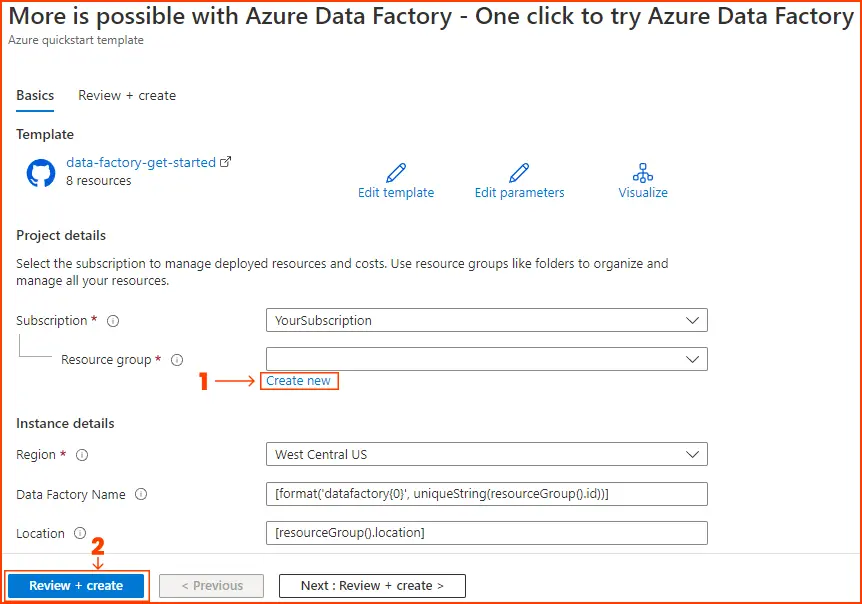
- Log in to the Azure portal and navigate to “Try it Now” button, and you will be redirected to the configuration page displayed in the image below to deploy the template. Here, simply create a new resource group, leaving all other values at their default settings.Then, click on “Review + create” followed by “Create” to deploy the resources.

Image Source: azure.microsoft.com
- Log in to the Azure portal and navigate to “Try it Now” button, and you will be redirected to the configuration page displayed in the image below to deploy the template. Here, simply create a new resource group, leaving all other values at their default settings.Then, click on “Review + create” followed by “Create” to deploy the resources.
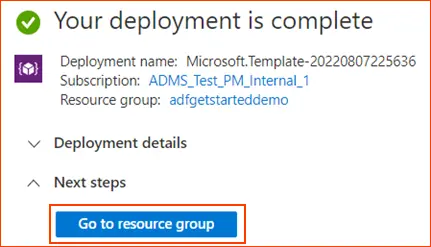
- Once your deployment is completed , then click on “Go to Resource Group”

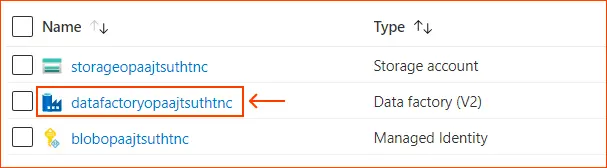
Image Source: azure.microsoft.com - In the resource group, you will find the newly created data factory, Azure Blob Storage account, and managed identity from the deployment.
-

Image Source: azure.microsoft.com - Fill out the details like name, subscription, and resource group (where you want to organize your ADF resources).
- Click “Create” to provision your ADF instance.
2. Access ADF Studio
-
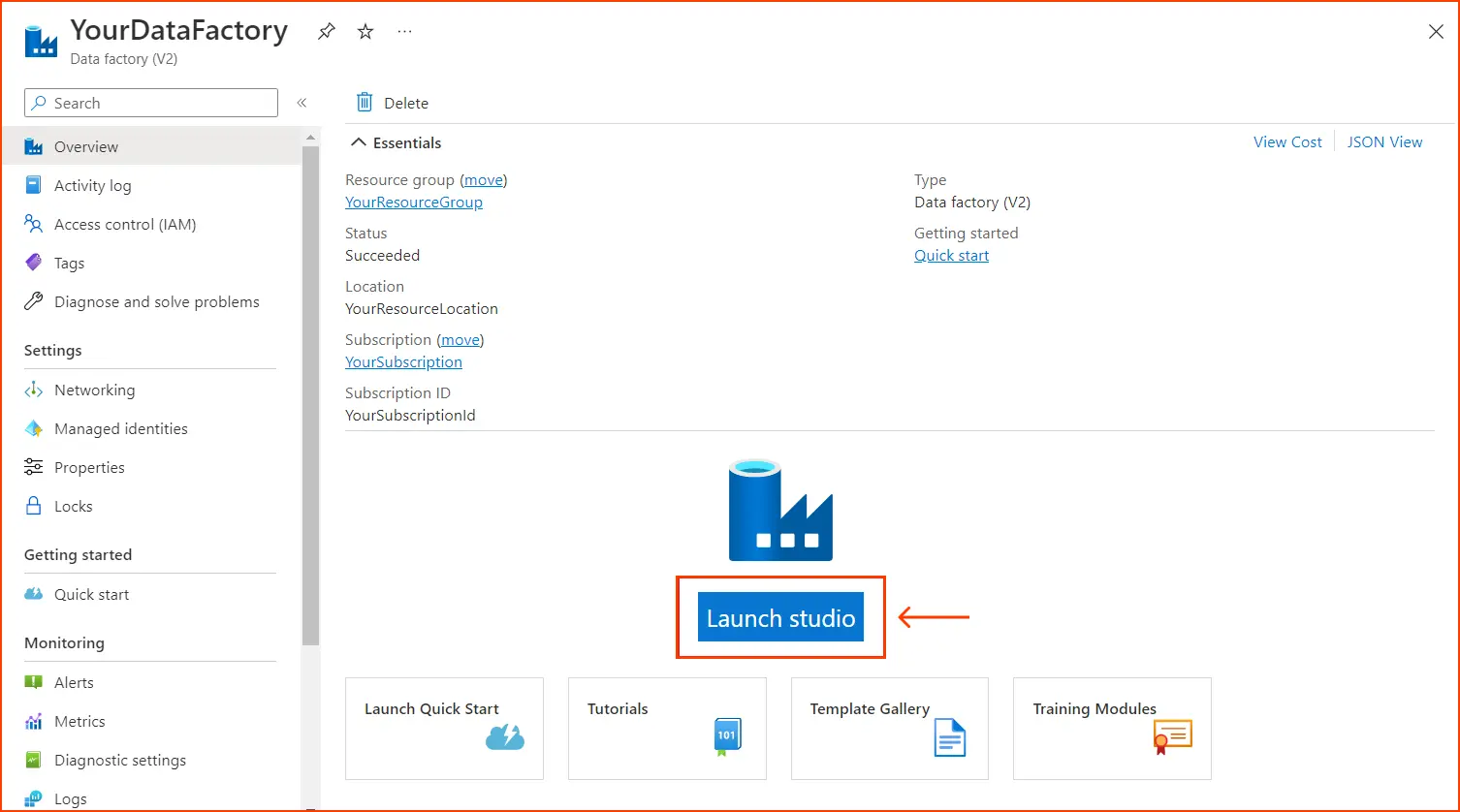
- Once your ADF is created, navigate to it in the Azure portal.
- Choose the data factory within the resource group to inspect it. Next, click on the “Launch Studio” button to proceed.
-

Image Source: azure.microsoft.com
-
- Navigate to the Author tab, then select the Pipeline generated by the template. Afterwards, examine the source data by choosing “Open.”
-

Image Source: azure.microsoft.com - Give your pipeline a name and choose a suitable execution model (Trigger-based or Scheduled).
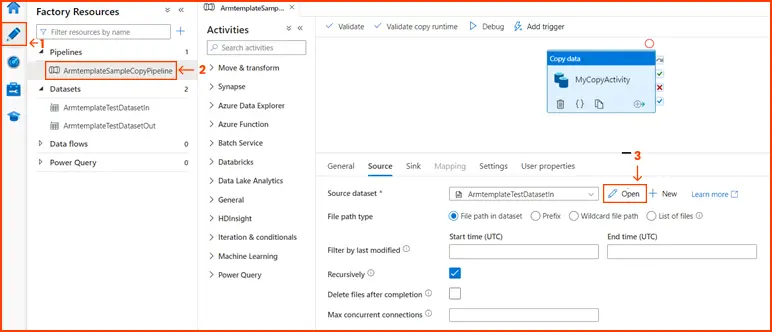
-
- ADF offers a drag-and-drop interface where you can add various activities to your pipeline.
4. Configure Data Sources
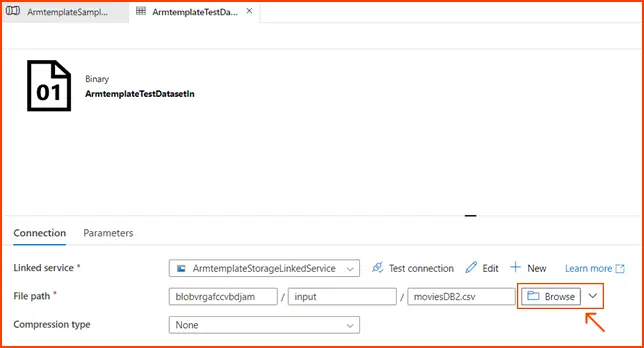
-
- Within the source dataset, click on “Browse” to access it. Take note of the “moviesDB2.csv” file, which has already been uploaded into the input folder.
-

Image Source: azure.microsoft.com 
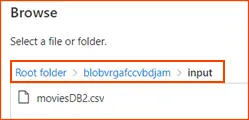
6. Set Up Data Destination
-
- In the pipeline, add an activity for the destination where the transformed data will be loaded. Similar to data sources, use connectors to connect to your desired destination like Azure Synapse Analytics, Azure SQL Database, or even on-premises storage.
7. Schedule or Trigger Your Pipeline
-
- Depending on your needs, configure the pipeline execution. For automated data movement, set up a schedule (daily, hourly, etc.). Alternatively, use triggers like new data arrival in a source to initiate the pipeline execution.
- Select Add Trigger, and then Trigger Now.
- In the right pane under Pipeline run, select OK.

Monitor the Pipeline
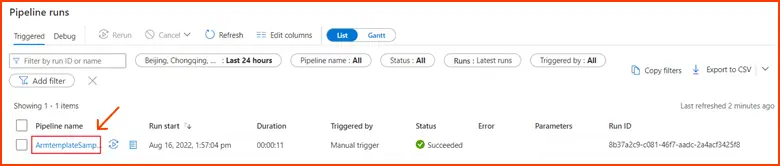
- Navigate to the Monitor tab.
- Here, you can observe a summary of your pipeline runs, including details like start time, status, and more.
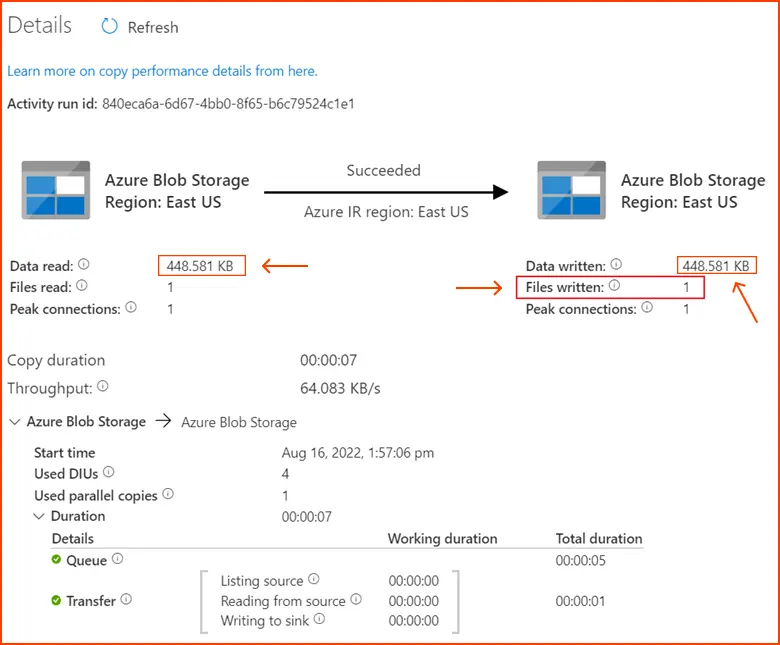
8. Test and Publish
- Click on “details,” and you’ll see the comprehensive copy process displayed. From the results, note that the data read and written sizes match, and one file was read and written. This confirms that all the data has been successfully copied to the destination.
-

Image Source: azure.microsoft.com - Once satisfied, click “Publish” to make your pipeline live and start processing data according to your configuration.
Conclusion
I hope this blog post has given you a solid understanding of Azure Data Factory (ADF). We have explored its key features, the benefits it offers, how to create and real-world data integration uses cases & challenges.
Whether you’re a data analyst or an engineer, ADF can empower you to streamline data movement and transformation. With its user-friendly interface and vast capabilities, ADF simplifies the process of unlocking valuable insights from your data, regardless of its source or format.
So, are you ready to harness the power of ADF and transform your data into actionable intelligence? Explore the resources offered by Whizlabs and dive deeper into the world of Azure Data Factory!
- 7 Pro Tips for Managing and Reducing Datadog Costs - June 24, 2024
- Become an NVIDIA Certified Associate in Generative AI and LLMs - June 12, 2024
- What is Azure Data Factory? - June 5, 2024
- An Introduction to Databricks Apache Spark - May 24, 2024
- What is Microsoft Fabric? - May 16, 2024
- Which Kubernetes Certification is Right for You? - April 10, 2024
- Top 5 Topics to Prepare for the CKA Certification Exam - April 8, 2024
- 7 Databricks Certifications: Which One Should I Choose? - April 8, 2024