
AWS data engineering involves designing and implementing data solutions on the Amazon Web Services (AWS) platform. For those aspiring to become AWS data engineers, cracking the interview is somehow difficult. Don’t worry, we’re here to help you!
In this blog, we present a comprehensive collection of top AWS data engineer interview questions for you. These questions have been carefully selected to cover a wide range of topics and concepts that are relevant to the AWS Data Engineer role. Understanding the concepts behind these questions would help you to successfully go through the interview.
If you are planning to become AWS Data Engineer, I would recommend you to pass AWS Certified Data Engineer Associate. This exam could potentially cover many topics related to the data engineer role.
Let’s dive in!
Top 25 AWS Data Engineer Interview Questions and Answers
Below are some AWS data engineer questions and answers that you might encounter during an interview:
1. What is the role of a data engineer at AWS?
As an AWS Data Engineer, your core responsibility is to plan, create, manage, and enhance an organization’s data infrastructure. This covers everything from assembling systems for data processing and storage to connecting diverse data sources and ensuring the efficiency and dependability of the data pipeline.
2. What are the common challenges faced by AWS data Engineers?
Data engineers at AWS frequently deal with issues including handling complicated data pipelines, managing massive amounts of data, integrating various data sources, and maintaining the performance and dependability of the data infrastructure. Working with remote systems, addressing privacy and security issues, and handling real-time data processing could present additional difficulties.
3. What are the tools used for data engineering?
The following are some of the tools that are employed for doing the data engineering tasks:
- Data ingestion
- Storage
- Data integration
- Data visualization tools
- Data warehouse
4. What exactly is Amazon S3?
Amazon Simple Storage Service (Amazon S3), is an object storage service that offers scalable and affordable data storage. Data lakes, backup and recovery, and disaster recovery are among its frequent uses.
5. What does Amazon EC2 do?
A web service called Amazon Elastic Compute Cloud (Amazon EC2) offers scalable computing capability in the cloud. Batch processing, web and application hosting, and other compute-intensive operations are among its frequent uses.
6. What is Amazon Redshift?
Amazon Redshift is a fully managed data warehouse that helps to process large volumes of data easily and affordably. It is frequently utilized for corporate intelligence and data warehousing activities.
7. What is Amazon Glue, and how does it make the Extract, Transform, and Load (ETL) process easier?
AWS Data migration between data stores is made simple with a fully managed ETL solution called AWS Glue. It eliminates manual coding by automating the extract, transform, and load procedures. Glue crawlers can find and categorize information from various data sources. Glue’s ETL processes can transform and upload the data into target data storage. This speeds up the creation of data pipelines and streamlines the ETL process.
8. What is the role of Amazon Quicksight in data visualization for AWS data engineering solutions?
Amazon QuickSight is a fully managed business intelligence service that can generate and distribute interactive reports and dashboards. QuickSight can be used in data engineering to display data produced by data pipelines and connect to a variety of data sources, including those on AWS. It offers a user-friendly interface for building visualizations, enabling people to learn from their data without requiring a deep understanding of code or analysis.
9. Describe the idea behind AWS Data Pipeline and how it helps to coordinate data activities.
AWS Data Pipeline is a web service that facilitates the coordination and automation of data transfer and transformation across various AWS services and data sources that are located on-premises. It makes complex data processing processes easier to handle by enabling you to build and schedule data-driven workflows. When it comes to data engineering, data pipelines are especially helpful for organizing tasks like data extraction, transformation, and loading (ETL).
10. How do data engineering migrations benefit from the use of AWS DMS (Database Migration Service)?
AWS DMS makes it easier to move databases to and from Amazon Web Services. DMS is frequently used in data engineering to migrate databases, either across different cloud database systems or from on-premises databases to the cloud. By controlling schema conversion, and data replication, and guaranteeing little downtime throughout the move, DMS streamlines the process.
11. How does AWS Glue support schema evolution in data engineering?
AWS Glue facilitates the evolution of schemas by permitting modifications to data structures over time. Glue can dynamically adapt its understanding of the data structure whenever fresh data with varied schemas arrives. Because datasets may vary over time, flexibility is essential in data engineering. Glue’s ability to adjust to schema changes makes managing dynamic, changing data easier.
12. Describe the role that AWS Data Lakes play in contemporary data engineering architectures.
AWS Centralized repositories known as “data lakes” let you store data of any size, both structured and unstructured. They enable effective data processing, analysis, and storage, which lays the groundwork for developing analytics and machine learning applications. Data Lakes are essential for managing and processing heterogeneous datasets from several sources in data engineering.
13. How can AWS CodePipeline be utilized to automate a CI/CD pipeline for a multi-tier application effectively?
Automating CI/CD pipeline for a multi-tier application can be done effectively by following the below steps:
- Pipeline Creation: Begin by establishing a pipeline within AWS CodePipeline, specifying the source code repository, whether it’s GitHub, AWS CodeCommit, or another source.
- Build Stage Definition: Incorporate a build stage into the pipeline, connecting to a building service such as AWS CodeBuild. This stage will handle tasks like code compilation, testing, and generating deployable artifacts.
- Deployment Stage Setup: Configure deployment stages tailored to each tier of the application. Utilize AWS services like CodeDeploy for automated deployments to Amazon EC2 instances, AWS Elastic Beanstalk for web applications, or AWS ECS for containerized applications.
- Incorporate Approval Steps (Optional): Consider integrating manual approval steps before deployment stages, particularly for critical environments. This ensures quality control and allows stakeholders to verify changes before deployment.
- Continuous Monitoring and Improvement: Monitor the pipeline’s performance and adjust as needed. Emphasize gathering feedback and iterating on the deployment process to enhance efficiency and effectiveness over time.
14. How to handle continuous integration and deployment in AWS DevOps?
Managing continuous integration and deployment in AWS DevOps involves using AWS Developer Tools effectively. Start by storing and versioning your application’s source code using these tools.
Next, employ services like AWS CodePipeline to orchestrate the build, testing, and deployment processes. CodePipeline is the core, integrating seamlessly with AWS CodeBuild for compiling and testing code, and AWS CodeDeploy for automating deployments across different environments. This structured approach ensures smooth and automated workflows for continuous integration and delivery.
15. What is AWS Glue Spark Runtime, and how does it utilize Apache Spark for distributed data processing?
AWS Glue Spark Runtime is the foundational runtime engine for AWS Glue ETL jobs. It utilizes Apache Spark, an open-source distributed computing framework, to process extensive datasets concurrently. By integrating with Spark, Glue can horizontally scale and effectively manage intricate data transformations within data engineering workflows.
16. What role does AWS Glue Data Wrangler play in automating and visualizing data transformations within ETL workflows?
AWS Glue Data Wrangler streamlines and visually represents data transformations by offering a user-friendly interface for constructing data preparation workflows. It furnishes pre-configured transformations and enables users to design ETL processes visually, eliminating the need for manual code writing. In the realm of data engineering, Data Wrangler expedites and simplifies the creation of ETL jobs, thereby broadening its accessibility to a wider user base.
17. What is the purpose of AWS Glue Schema Evolution?
AWS Glue Schema Evolution serves as a capability that enables the Glue Data Catalog to adjust to changes in the structure of the source data over time.
Whenever modifications occur to the schema of the source data, Glue can automatically revise its comprehension of the schema. This capability facilitates ETL jobs to effortlessly handle evolving data. Such functionality is paramount in data engineering for effectively managing dynamic and evolving datasets.
18. What is the importance of AWS Glue DataBrew’s data profiling features?
AWS Glue DataBrew’s data profiling features enable users to examine and grasp the attributes of datasets thoroughly. Profiling encompasses insights into data types, distributions, and potential quality concerns. In the realm of data engineering, data profiling proves valuable for obtaining a holistic understanding of the data and pinpointing areas necessitating cleaning or transformation.
19. What is the role of AWS Glue Dev Endpoint?
AWS Glue Dev Endpoint serves as a development endpoint enabling users to iteratively develop, test, and debug ETL scripts interactively, utilizing tools such as PySpark or Scala. It furnishes an environment for executing and validating code before deployment in production ETL jobs.
In the domain of data engineering, the Dev Endpoint streamlines the development and debugging phases, thereby enhancing the efficiency of ETL script development.
20. What is AWS Glue Crawler?
The role of AWS Glue Crawler is pivotal in data engineering as it handles the automatic discovery and cataloging of data metadata. By scanning and extracting schema details from diverse data repositories, it populates the Glue Data Catalog. This component is vital for maintaining a centralized and current metadata repository, facilitating streamlined data discovery and processing workflows.
21. What is an operational data store (ODS)?
An operational data store (ODS) serves as a centralized database that gathers and organizes data from multiple sources in a structured manner. It acts as a bridge between source systems and data warehouses or data marts, facilitating operational reporting and analysis.
Incremental data loading is a strategy employed to update data in a target system with efficiency. Instead of reloading all data each time, only the new or modified data since the last update is processed. This method minimizes data transfer and processing requirements, leading to enhanced performance and reduced resource usage.
22. What are the stages and types of ETL testing
ETL testing is vital for ensuring the accuracy, completeness, and reliability of data processing pipelines. Here are the common stages and types of ETL testing:
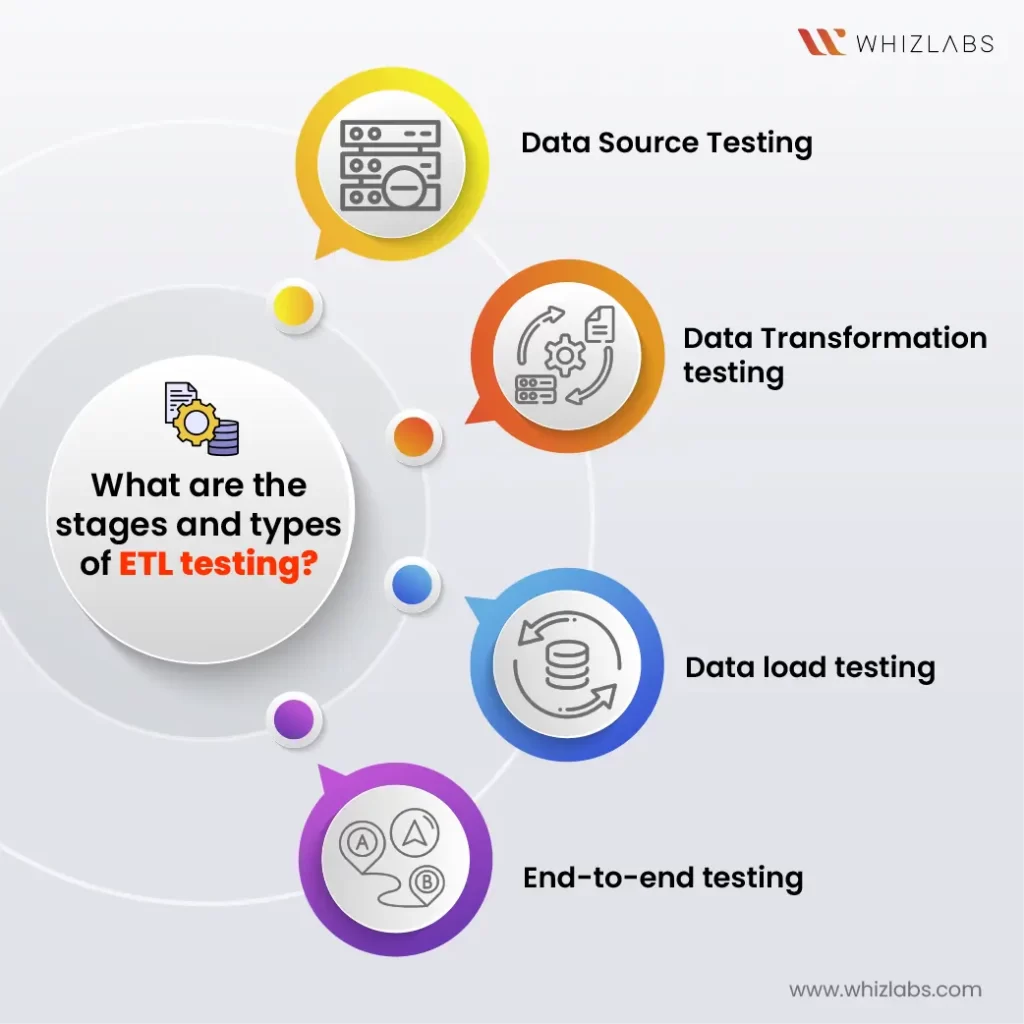
- Data source testing: This stage involves validating the data sources to ensure that they are reliable and accurate. It includes verifying data integrity and confirming that the data meets the expected quality standards.
- Data transformation testing: In this stage, the focus is on ensuring that the data transformations are applied correctly as per the defined business rules. It involves verifying that the data is transformed accurately and consistently according to the requirements.
- Data load testing: This stage involves testing the loading of data into the target system. It includes verifying the integrity of the data loaded into the target system and ensuring that it matches the source data.
- End-to-end testing: This comprehensive testing stage validates the entire ETL process from source to target. It includes testing the entire data flow, including data extraction, transformation, and loading, to ensure that the process is functioning correctly and producing the expected results.
By performing these stages and types of ETL testing, organizations can ensure the reliability and accuracy of their data processing pipelines, leading to better decision-making and improved business outcomes.
23. How does AWS support the creation and management of data lakes?
AWS offers a variety of services and tools designed specifically for building and maintaining data lakes, which serve as centralized repositories for storing structured, semi-structured, and unstructured data in its raw format. These include:
- Amazon S3: A highly scalable object storage service that allows for the storage and retrieval of data within a data lake.
- AWS Glue: A fully managed ETL (Extract, Transform, Load) service that facilitates data integration and transformation tasks within the data lake environment.
- AWS Lake Formation: A specialized service aimed at simplifying the process of building and managing secure data lakes on the AWS platform.
You can take advantage of the AWS data engineer practice test to become familiar with the above AWS services.
24. What are the partitioning and data loading techniques employed in AWS Redshift?
In AWS Redshift, partitioning is a method utilized to segment large datasets into smaller partitions based on specific criteria such as date, region, or product category. This enhances query performance by reducing the volume of data that needs to be scanned.
Regarding data loading techniques, AWS Redshift supports:
- Bulk data loading: This involves importing large volumes of data from sources like Amazon S3 or other external data repositories.
- Continuous data ingestion: Redshift enables ongoing data ingestion using services like Amazon Kinesis or AWS Database Migration Service (DMS), ensuring real-time updates to the data warehouse.
- Automatic compression and columnar storage: Redshift employs automatic compression and columnar storage techniques to optimize data storage and retrieval efficiency.
25. What is AWS Redshift and what are its key components?
AWS Redshift is a fully managed data warehousing solution provided by AWS, capable of handling petabyte-scale data.
Its critical components include:
- Clusters: These are groups of nodes (compute resources) responsible for storing and processing data within Redshift.
- Leader node: This node serves as the coordinator, managing and distributing queries across the compute nodes within the cluster.
- Compute nodes: These nodes are dedicated to executing queries and performing various data processing tasks within the Redshift environment.
Conclusion
Hope this article provides a comprehensive roadmap of AWS Cloud Data Engineer interview questions suitable for candidates at different levels of expertise.
It covers questions ranging from beginners who are just starting to explore AWS to seasoned professionals aiming to advance their careers. These interview questions not only equip you to address interview questions but also encourage you to delve deeply into the AWS platform, enriching your comprehension and utilization of its extensive capabilities.
Make use of the AWS data engineer practice exam to experience the real-time exam settings and boost your confidence level.
- Top 25 AWS Data Engineer Interview Questions and Answers - May 11, 2024
- What is Azure Synapse Analytics? - April 26, 2024
- AZ-900: Azure Fundamentals Certification Exam Updates - April 26, 2024
- Exam Tips for AWS Data Engineer Associate Certification - April 19, 2024
- Maximizing Cloud Security with AWS Identity and Access Management - April 18, 2024
- A Deep Dive into Google Cloud Database Options - April 16, 2024
- GCP Cloud Engineer vs GCP Cloud Architect: What’s the Difference? - March 22, 2024
- 7 Ways to Double Your Cloud Solutions Architect Role Salary in 12 Months - March 7, 2024
