
Apache Kafka offers a robust and scalable solution for handling large-scale data streams with ease.
In this blog post, you will delve into the key building blocks of Kafka, including topics, partitions, and brokers, which form the backbone of the platform.
In the end, you will have a solid understanding of the basics of Apache Kafka, paving the way for you to explore its myriad of use cases and delve into advanced topics. So, fasten your seatbelt and get ready to dive into the fascinating world of Apache Kafka.
Let’s explore!
What is Apache Kafka?
An event streaming platform named Apache Kafka is employed to collect, analyze, store, and merge data at scale. Integrated streaming, processing streams, integration of data, and pub/sub messaging are some of the application use cases.
It uses optimized query execution and cache in memory for quick analytic queries across any size of data. It offers code reuse across different workloads, including batching, query interaction, real-time analytics, machine learning, and network processing. Development APIs can be offered in various formats like Java, Scala, Python, and R.
Kafka offers fault tolerance by means of data replication across multiple brokers. Each partition has a leader and multiple replicas, ensuring that if a broker fails, another replica can take over. This replication mechanism ensures data durability and availability.
Apache Spark
Spark, a powerful data processing engine, has indeed revolutionized the world of big data analytics. By addressing the limitations of Hadoop MapReduce, Spark has emerged as a game-changer, enabling faster and more efficient data processing.
One of the significant challenges of MapReduce is the sequential multi-step process it follows for job execution, which involves disk reads and writes at each step. This disk I/O latency contributes to slower job execution times. Spark, on the other hand, takes advantage of in-memory processing, significantly reducing the number of steps required for job completion.
By performing operations in memory, Spark eliminates the need for repeated disk reads and writes, resulting in much faster execution. With Spark, data is read into memory, operations are performed, and the results are written back in a single step. This streamlined process greatly enhances the speed and efficiency of data processing.
Apache Topics
Apache Kafka topics help the organization take care of the flow of data streams. Think of topics as virtual channels or categories where data is published and consumed by various components within the Kafka ecosystem. They provide a logical representation of specific data streams that can be partitioned and distributed across Kafka brokers.
Data in Kafka is organized into topics. Topics are divided into partitions, which are individual ordered logs of messages. Each partition can be replicated across multiple brokers for fault tolerance and durability.
When data is produced by a publisher (known as a producer), it is assigned to a specific topic. Each message within a topic is identified by a unique offset, which represents its position within the topic’s partition. Partitions are individual units of data storage within a topic, allowing for parallel processing and scalability.
Producers are applications or systems that write data to Kafka topics. They can be publishers of real-time events or data feeds. Consumers are applications or systems that read and process the data from Kafka topics. They can process the data in real-time or store it for later analysis.
Consumers, on the other hand, subscribe to specific topics to receive and process the published data. They can read from one or more partitions simultaneously, allowing for high throughput and parallel consumption. Each consumer keeps track of its progress by maintaining its offset, indicating the last processed message in a partition.
Topics in Apache Kafka are highly flexible and dynamic. They can be created, modified, and deleted on demand, making it easy to adapt to changing data requirements. Additionally, topics can be replicated across multiple Kafka brokers, ensuring fault tolerance and data availability.
They enable producers to publish data and consumers to subscribe to and process it. With partitioning and replication, topics provide scalability, fault tolerance, and high throughput, making them a fundamental component of the Kafka ecosystem.
Apache streams
It provides a streamlined approach for building applications and microservices by leveraging the storage capabilities of an Apache Kafka cluster.
One of the key advantages of Kafka Streams is its ability to seamlessly integrate input and output data with the Kafka cluster. This means that data processing can be performed directly within the Kafka ecosystem, eliminating the need for separate data storage and processing systems.
By using Kafka Streams, developers can leverage their existing Java and Scala skills to write and deploy applications on the client side. This simplicity of development allows for faster application creation and deployment cycles.
Kafka has built-in support for stream processing with its Kafka Streams API. It allows developers to process and transform data streams in real time, perform windowed computations, and build event-driven applications.
Furthermore, Kafka Streams benefit from the robustness and scalability of Kafka’s server-side cluster technology. This ensures that the applications built with Kafka Streams can handle large volumes of data and support high levels of throughput.
Apache Kafka Architecture
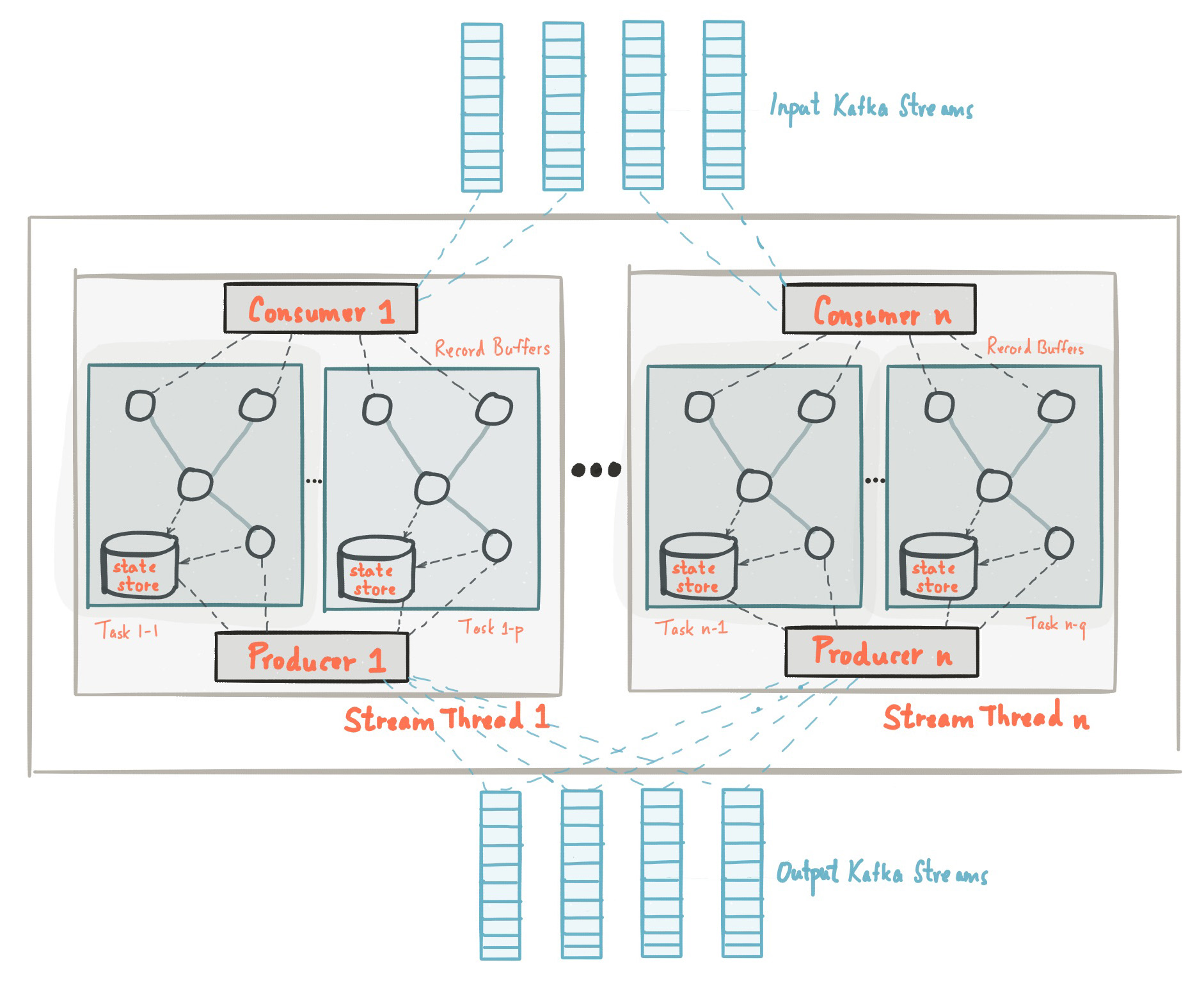
Kafka Streams ease the application development process by the usage of Kafka producer and consumer libraries and utilizing the native capabilities of Kafka to provide data parallelism, distributed coordination, fault tolerance, and operational simplicity. In this section, we illustrate how Kafka Streams works underneath the covers.
The advent of Kafka streams just simplifies the application development by just constructing on Kafka produced and libraries of the consumers and it can definitely leverage the native capacities of the Kafka to provide data parallelism, operational simplicity, and fault tolerance.
Apache stream partitioning
To store and transport the partitioned data of Kafka, the messaging layer will be utilized. The Kafka streams divide the data for processing. In both cases, the partition can enable data elasticity, locality, high performance, scalability, and fault tolerance.
The Kafka streams employ partition concepts and utilize tasks as logical into parallelized models on the basis of topics partition. They can closely relate the Kafka streams and Kafka in terms of parallelism.
The topology of the application processor will be partitioned into multiple tasks. Particularly, kafka streams create fixed tasks on the basis of input application stream partition, in which each task will be allocated to a list of partitions from the Kafka topics. The partition process cannot be changed if each task comprises of fixed parallelism unit of application.
You can instantiate the tasks on the basis of the assigned partitions to maintain a buffer for assigned partitions and can process the messages one time from the recorded buffers. As a result, the streamlined tasks will be processed in an instant as well a parallel manner without the need for any human intervention.
It’s essential to remember that Kafka Streams is a library that “runs” wherever its stream processing application runs. Tasks can be automatically split by the library to the currently running application instances. Numerous instances of the application are operated either on the same system or scattered across many machines. Tasks are always given the same stream partitions to consume from, thus if one application instance fails, all of its assigned tasks will instantly restart on other instances.
Apache Kafka Use cases
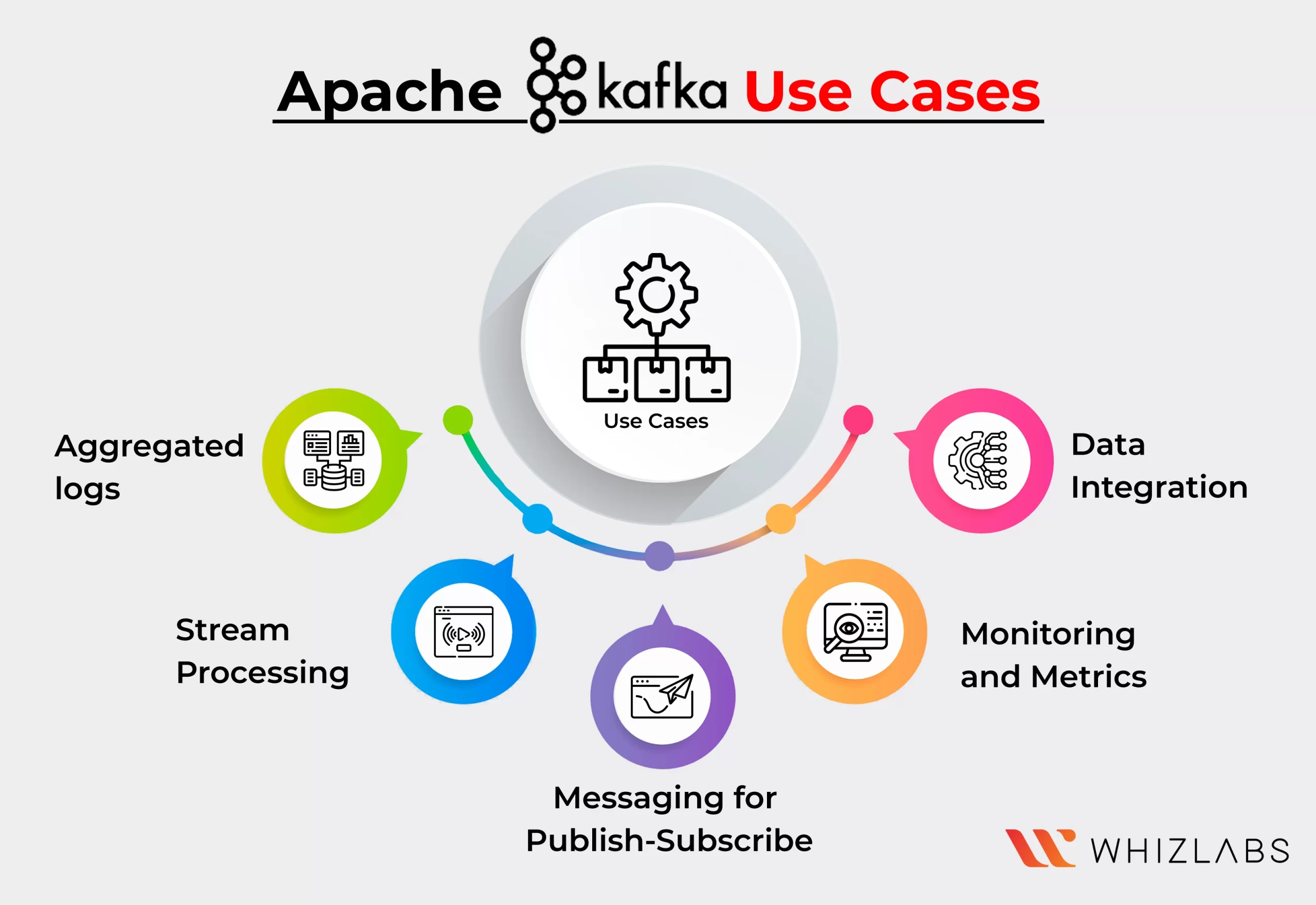
Apache Kafka is a powerful distributed streaming platform that has gained significant popularity due to its versatility and scalability. It provides a robust solution for real-time data processing, messaging, and event streaming. Here are some use cases that are used by Apache Kafka:
Data Integration
Kafka may link to almost any other data source, whether on the cloud, contemporary databases, or classic enterprise information systems. With built-in data connectors, it creates a practical point of interaction without burying logic or routing inside a fragile and centralized infrastructure.
Monitoring and Metrics
Operational data monitoring frequently makes use of Kafka. To create centralized feeds with real-time measurements, statistics from remote applications must be aggregated.
Aggregated logs
Modern systems are frequently distributed systems, hence it is necessary to centralize information recorded from all of the system’s parts into one location. By aggregating data from all sources, regardless of format or volume, Kafka frequently acts as a single source of truth.
Stream Processing
One of Kafka’s primary competencies is the execution of real-time calculations on event streams. Kafka retains, stores, and determines streams of data while it is generated, at any scale, to offer real-time data processing and dataflow programming.
Messaging for Publish-Subscribe
Kafka functions well as a modernized version of the conventional message broker since it is a shared pub/sub-messaging system. Kafka is a flexible and extensible solution to get the job done whenever a process that creates events needs to be separated from the workflow or from procedures receiving the events.
Also Read : Apache Kafka Tutorial – A Quick Introduction
Apache Kafka advantages
Here are some advantages of Apache Kafka:
- High Throughput and Scalability: Kafka is designed to handle high volumes of data and support high-throughput data streams. It can efficiently handle millions of messages per second, making it suitable for demanding use cases.
- Fault-Tolerant and Durability: Kafka ensures fault tolerance and data durability by replicating data across multiple brokers. This replication mechanism allows for seamless failover and ensures data availability even in the event of broker failures.
- Real-time Data Processing: Kafka enables real-time data processing by providing low-latency message delivery. It allows applications to consume and process data as soon as it is available, enabling real-time analytics, monitoring, and decision-making.
- Scalable and Distributed Architecture: Kafka’s distributed architecture allows it to scale horizontally by adding more brokers to the cluster. This scalability ensures that Kafka can handle growing data volumes and processing requirements.
- Message Retention and Replay: Kafka retains messages for a configurable period of time, allowing consumers to replay or reprocess past data. This feature is valuable for scenarios where data needs to be reprocessed or when new applications join the system.
- Stream Processing: Kafka’s Streams API enables developers to build real-time stream-processing applications. It provides capabilities for event-driven processing, windowed computations, and stateful transformations on data streams.
- Ecosystem and Integration: Kafka has a rich ecosystem with connectors that facilitate seamless integration with other systems. These connectors enable easy data ingestion into Kafka or export data from Kafka to external systems, such as databases, data lakes, or analytics platforms.
FAQs
Is it easy to learn Kafka?
Overall, Apache Kafka is a strong and popular solution for businesses that are data-driven. It is easy to learn for those familiar and experienced with distributed systems.
Is coding necessary for Apache Kafka?
The users should be familiar with the fundamentals of Java while going for Kafka. When working with Apache Kafka, the following conditions must be met: such as fundamental knowledge of Notepad, IntelliJ IDEA, Eclipse and JDK 1.8 is necessary.
What should I learn before Kafka?
Before continuing the Apache Kafka, you should be well-versed in Java, Scala, Distributed Messaging Systems, and the Linux environment.
Conclusion
Throughout this beginner’s guide, we have explored the fundamental concepts and key components that make Kafka a go-to choice for handling real-time data streams.
By grasping the foundational concepts of Apache Kafka presented in this blog post, you are now equipped with the knowledge to dive deeper into this exciting streaming platform.
Whether you are venturing into real-time data processing, building event-driven architectures, or exploring data integration possibilities, Kafka offers a wealth of opportunities to explore and unleash the potential of your data.
If you have any questions about this blog post, feel free to ping us!
- Study Guide DP-600 : Implementing Analytics Solutions Using Microsoft Fabric Certification Exam - June 14, 2024
- Top 15 Azure Data Factory Interview Questions & Answers - June 5, 2024
- Top Data Science Interview Questions and Answers (2024) - May 30, 2024
- What is a Kubernetes Cluster? - May 22, 2024
- Skyrocket Your IT Career with These Top Cloud Certifications - March 29, 2024
- What are the Roles and Responsibilities of an AWS Sysops Administrator? - March 28, 2024
- How to Create Azure Network Security Groups? - March 15, 2024
- What is the difference between Cloud Dataproc and Cloud Dataflow? - March 13, 2024
