

Hadoop is a hot technology that primarily deals with petabytes of data for high-level analysis in enterprise applications. However, enterprises often work in a time-bound situation that requires fast analysis of collected data over a limited period. Hadoop MapReduce is a complicated tool for analysis purpose. Along with it, you need some programming language skills to explore data in MapReduce.
Here comes the need for data query language like SQL for data extraction, analysis, and processing. Although tried and tested with big data front end, certainly SQL does not fit well with Hadoop data store. It is a general purpose database language and not built solely for analytical purpose. On the other hand, the query language HQL or HiveQL of Apache Hive works well on historical data for analytical querying. Moreover, Apache Hive gives you an opportunity to have a complete control over data in a better way.
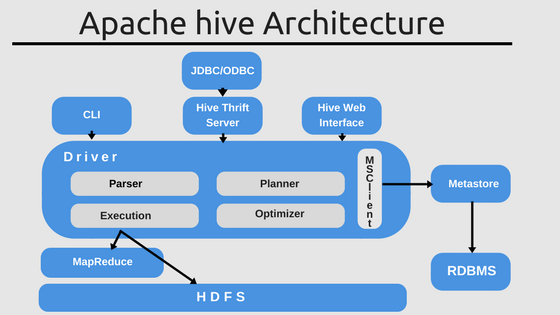
Why is Apache Hive Faster than SQL?
Organizations affinity towards open source brings the addition of Apache Hive to Hadoop family for the analytical query. It is important to realize that Apache Hive follows a data warehouse infrastructure which is built on the top of Apache Hadoop. The primary use of Apache Hive in Hadoop is to summarize and to perform an ad-hoc query on data along with analyzing large datasets. In addition to that, you will get a chance to project a structure onto the collected data in Hadoop. Furthermore, Apache Hive provides a similar interface to receive data in Hadoop cluster. Hence, it is a great way to start faster data analyzing.
Let’s look into the technical aspects that make Hive faster during the processing of queries.
Partitioning of Table
Hive significantly improves performance optimization using its partitioning techniques which can be static or dynamic. Hadoop data store (that is HDFS) stores petabytes of data that a Hadoop user needs to query for data analysis. No doubt, it is a significant burden! In Partitioning method, Hive divides all the stored table data into multiple partitions. Each partition targets a specific value of partition column. Here the values inside the column are the records present in the HDFS. Hence, when you query a table, in fact, you are going to query a partition of the table.
Apache Hive converts the particular SQL query into MapReduce job and then submits it to the Hadoop cluster. Consequently, you will return the query value. Hence, the partitioning process decreases the operational I/O time and decreases execution load. As a result, the overall performance increases markedly.
Bucketing
While dealing with large table data, it is possible that even partition size does not match with expected file size. Partitioning does not work in this case. To manage this Hive allows users to divide data set into more manageable parts rather subdivisions. Hive uses the Hash function here to subdivide the partitions.

Use of TEZ Engine
You can use Apache TEZ instead of MapReduce as an execution engine for Apache Hive. TEZ which is a developer API and framework to write native YARN applications provides highly optimized data processing feature. TEZ with Apache Hive works as a faster query engine. To demonstrate, this is a shared-nothing architecture where each processing unit comprises of its memory and disk resources and works independently.
Use of ORCFILE
ORCFile is a new table storage format that helps in significant speed improvements through different techniques like predicate push-down and compression. Apache Hive supports ORCFile for every Hive table and using such ORCFiles is extremely helpful in speeding up the execution.
Implementing Vectorization
Vectorization is an essential feature seen from Hive 0.13 onwards. This particular feature helps in batch execution of queries like joins, scans, filter, aggregations, etc.
Cost-based Optimization (CBO)
Cost-based optimization is Hive’s way to optimize physical and logical execution plan for each query. It uses query cost to optimize decisions for the order of joins, types of join to perform and others.
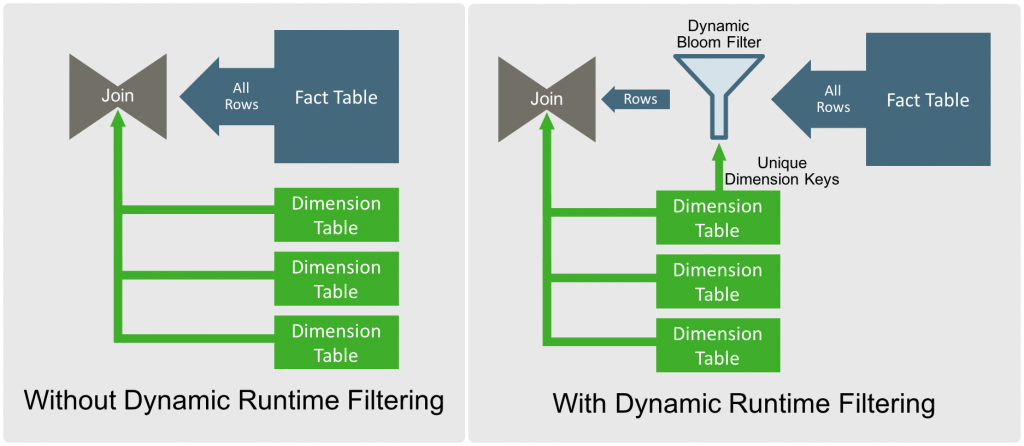
Dynamic Runtime Filtering
Dynamic Runtime Filtering of Apache Hive provides an enhanced fully dynamic solution for table data. With Dynamic Runtime Filtering, an automatic bloom filter works on actual dimension table values. In this case, the filter eliminates rows and skips the records that do not match. No join or shuffle operations happen further on that data. As a result, it saves a considerable amount of CPU and network consumption.
Introduction of Hive LLAP
LLAP (Low Latency Analytical Processing) is a second-generation big data system which combines optimized in-memory caching and persistent data query. LLAP SSD Cache which is a combination of RAM and SSD create a giant pool of memory. It makes computation happen in memory rather than on disk. Furthermore, it intelligently caches memory and shares computed data among the clients. Hive 2.0 with LLAP implementation launches queries almost instantly and in memory caching avoids unnecessary disk I/O. It makes Hive 2 practically 26x faster than Hive 1.
Explore Apache Hive Career to become a Hadoop Professional

Building a Hadoop career is everyone’s dream in today’s IT industry. Hence, if you’re already familiar with SQL but not a programmer, this blog might have shown you a roadmap to achieve a Hadoop skill. In reality, you can learn Apache Hive to be skilled in Hadoop tool belt as an option for data processing. Although SQL and Hive have some working differences, you will find a smooth transition once you enter the Hive world.
However, proper Apache Hive preparation is a must to achieve success as a Hadoop professional. There are many differences in constructs and syntaxes between Hive and SQL, and also you need to know architectural details with hands-on experiences. In this scenario, Hortonworks leads the industry with its data platform (HDP) for Hadoop. Its certification for HDPCA (HDP certified Administrator) is an excellent choice if you want a rock solid Apache Hive preparation.
Conclusion
To conclude, Whizlabs’ aim is to provide a complete guide for HDPCA exam with hands-on exercises. With this exam guide, you will receive full coverage on Automated Ambari Installation and Capacity Planning with which you will learn how to create Hive Metastore. Our core group of training service team assures you about the up to date training materials that sync up with Hortonworks certification syllabus. The entire guide not only gives you complete coverage of Apache Hive in Hadoop eco-system but also other components that work integrally with Hive. We assure the guide will help you in building your Apache hive career.
[divider /]
If you have any question/doubt just write below in comment section or write here, we will be happy to answer!
- Top 45 Fresher Java Interview Questions - March 9, 2023
- 25 Free Practice Questions – GCP Certified Professional Cloud Architect - December 3, 2021
- 30 Free Questions – Google Cloud Certified Digital Leader Certification Exam - November 24, 2021
- 4 Types of Google Cloud Support Options for You - November 23, 2021
- APACHE STORM (2.2.0) – A Complete Guide - November 22, 2021
- Data Mining Vs Big Data – Find out the Best Differences - November 18, 2021
- Understanding MapReduce in Hadoop – Know how to get started - November 15, 2021
- What is Data Visualization? - October 22, 2021

please bring cloudera cca-175 developer exam.
We are launching Cloudera CCA next week.
Privileged to read this informative blog on hadoop.Commendable efforts to put on research the hadoop.Please enlighten us with regular updates on hadoop.