

Understanding the best practices in AWS ML workflows will not only earn you an AWS certification but also enable you to optimize and automate ML models on an advanced level.
This article will explore some of the best practices when working with ML workflows and automation on AWS so that you’re not only successful in certification but also practical applications. Keep reading to find out more.
How Machine Learning (ML) Workflow on AWS Works?
To understand Machine Learning Workflow on AWS, there are several steps one needs to be conversant with for a model to be transformed from a concept to production. These steps include:
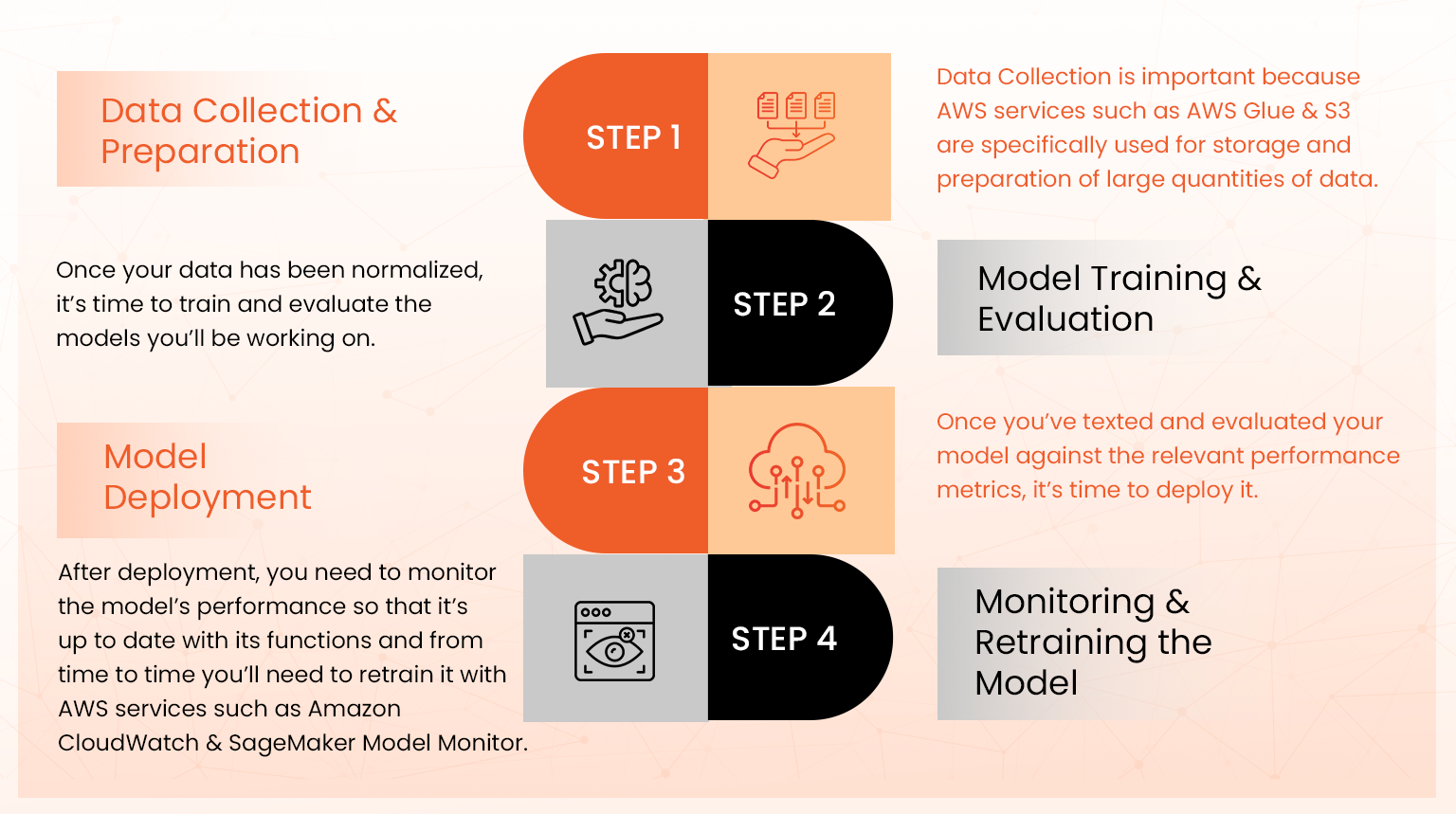
Step1: Data Collection & Preparation
Data Collection is important because AWS services such as AWS Glue & S3 are specifically used for storage and preparation of large quantities of data. AWS Glue together with Amazon SageMaker Data Wrangler also used to clean, transform and normalize the data collected into models you can train.
S3 serves your best as your central data repository because it will ensure scalability and security. It is recommended you partition or organize your data into folders named by category or period for easy access and querying. Also, use Amazon Kinesis for streamline data, which serves best in real-time data ingestion.
Step2: Model Training & Evaluation
Once your data has been normalized, it’s time to train and evaluate the models you’ll be working on. Amazon SageMaker is categorically used for this purpose.
You’ll be able to train models at scale through the in-built algorithms or you can customize your codes in alternative frameworks such as TensorFlow, Scikit-learn or PyTorch depending on what you’re comfortable with.
Once you’ve trained your model, you need to validate its performance through testing it against the test data using AWS tools. There are performance metrics that your model must meet at this stage for you to proceed to model deployment.
Step3: Model Deployment
Once you’ve texted and evaluated your model against the relevant performance metrics, it’s time to deploy it. You can choose between SageMaker or Lambda for low latency and real-time inference.
Autoscaling for SageMaker endpoints that is based on traffic patterns ensures cost-effectiveness and excellent performance for your models. SageMaker Batch Transform will come in handy when making predictions on large datasets for cases that don’t require real-time prediction.
Step4: Monitoring & Retraining the Model
After deployment, you need to monitor the model’s performance so that it’s up to date with its functions and from time to time you’ll need to retrain it with AWS services such as Amazon CloudWatch & SageMaker Model Monitor.
SageMaker Multi-Model Endpoints will be essential in managing multiple model versions with testing. Encrypt your data that is at rest and in transit with AWS Key Management Service (KMS). Use AWS Identity and Access Management (IAM) to restrict unauthorized access to models, datasets and ML resources.
The end-to-end process is fundamental to anyone trying to learn machine learning certification and it’s extensively covered under AWS certification examinations. Leverage AWS services that are compliant with cloud-based computing industry standards such as GDPR, HIPAA & SOC especially when dealing with sensitive data.
AWS ML Workflow Best Practices
Here are some of the best practices you can follow when designing and implementing AWS ML Workflow.
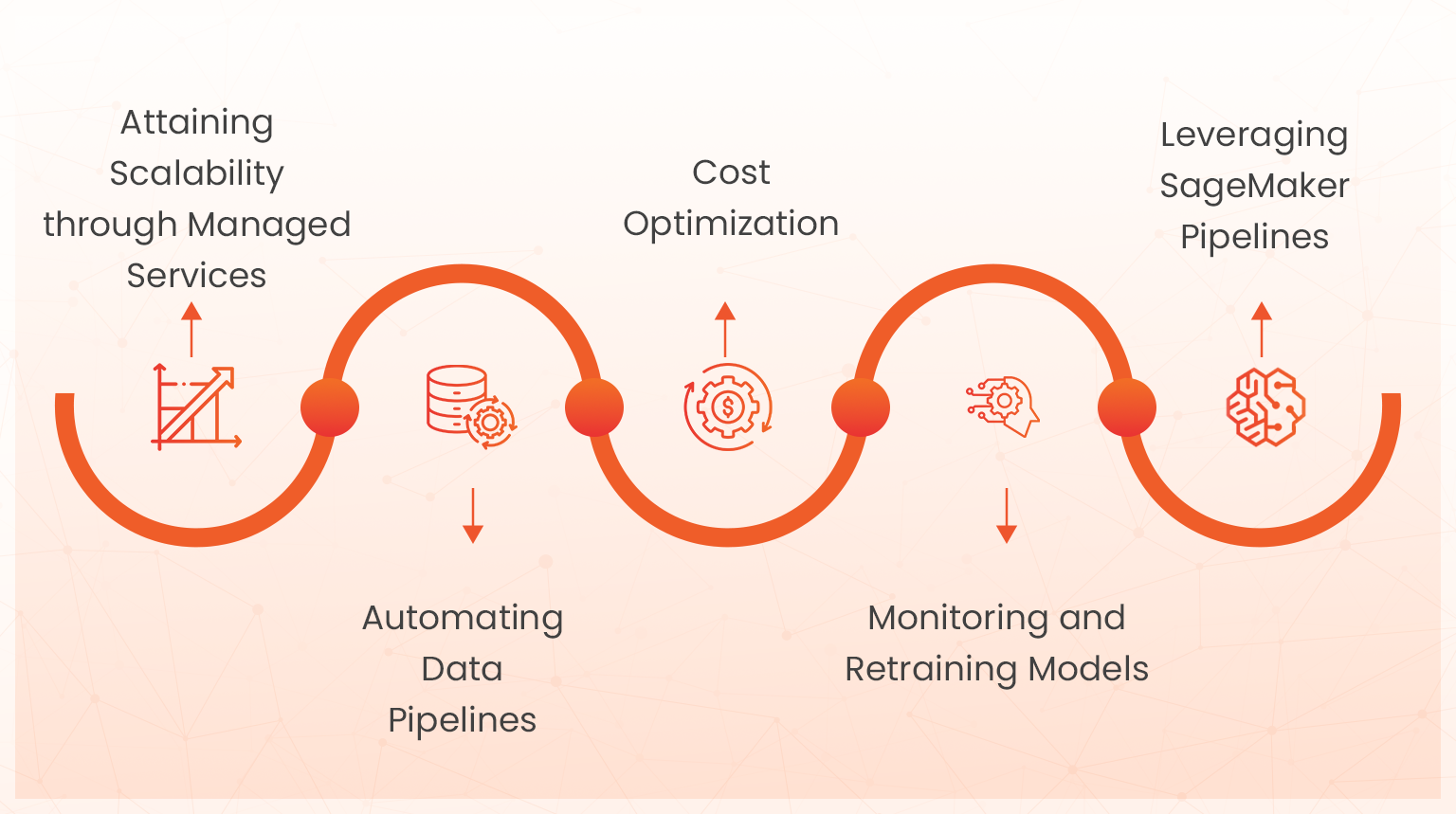
Attaining Scalability through Managed Services
Scalability is important when working with ML Workflow and AWS provides managed services through platforms such as the Amazon SageMaker so that you’re able to automate many parts of your model.
Your focus will be on model development & deployment since infrastructure concerns will have been eliminated. Managed services will automatically compute and store resources for training thereby saving your time and reducing your resources.
Automating Data Pipelines
Using AWS Glue, you can automate data pipelines during data preparation. This is significant because AWS Glue will help you transform, catalog and seamlessly integrate with AWS S3 and other similar services. Also, AWS Glue will automatically detect data schema and create ETL jobs ensuring up-to-date training of your models.
Cost Optimization
Running large scale machine learning activities are normally costly. However, AWS allows you to use Spot Instances provided by SageMaker which enables scaling of resources only when they’re deemed necessary. With Spot Training you’ll be able to save upto 90% on your training costs.
Monitoring and Retraining Models
Machine learning models do degrade over time because data is continuous in nature. AWS SageMaker Model monitor lets you keep your models updated with the recent data by easily detecting a shift in data and performance degradation. The model monitor tracks the changes in your model accuracy and triggers retraining prompts to stay on track with the latest data.
Leveraging SageMaker Pipelines
AWS SageMaker Pipelines automate each stage of machine learning in terms of management, building and end-to-end workflows. Creating automated pipelines makes handling your data during preprocessing much faster, your training much easier and a streamlined deployment of repetitive tasks to reduce human error.
10 Best Practices for AWS ML Certification
AWS Machine Learning certification requires huge preparation, hands-on experience, and deep expertise in how AWS services will integrate within the workflow of machine learning. This section will indicate some of the key best practices to be followed for good preparations and give some valuable tips:
Take a look at the Exam Guide
AWS provides an exam guide that gives five knowledge domains on which the exam is based. Those include data engineering, exploratory data analysis, modelling, and machine learning implementation and operation. Be sure to study all the topics listed in the guide for proper coverage.
Create a Study Plan
Organize your learning with a structured study plan. Divide the topics into comfortable sections, containing both theoretical learning and practical application that will help you bring in everything necessary for the examination.
Focus on Key Concepts
The exam will actually test deep knowledge about some very important concepts in machine learning – namely, model training, tuning, deployment, and monitoring. Also, give special attention to AWS-specific features for managing machine learning life cycles using SageMaker, Glue, and CloudWatch.
Hands-On Experience
Gaining real-world experience is crucial. Practice on live projects with the main AWS services: Amazon SageMaker for model building, AWS Glue for data preparation, and Amazon S3 to store your data.
Automation of Workflows
You should be set to automate workflows since this is one of the most key roles machine learning will play at AWS. You have to be comfortable driving the setup of ML pipelines and automating ETL workflows with services such as SageMaker and AWS Glue. It is expected that, by hands-on knowledge, you know how to automate such workflows, which likely will form part of the exams in the certification.
Optimize for Cost
AWS certification places much emphasis on such development of cost optimization. You are expected to understand resource allocation efficiency, especially on service resources like EC2 Spot Instances and Auto Scaling. Scoring in this section demands an understanding of when and how to use the techniques that save costs.
Master Data Management
Your skills in data management should be unparalleled. You will learn to effectively use Amazon S3, AWS Glue, and SageMaker Data Wrangler in handling and preparing data for machine learning workflows. Since Data Engineering is an essential section of the certification, focus on the understanding of how these services will work together to build a reliable pipeline.
Leverage AWS training resources
AWS provides both free and paid training courses that are directly aimed at setting candidates up for success in their certification. Use those resources, as they have a lot to say about the structure and the contents of the exam.
Study Documentation and Questions
In fact, most services are documented with how they are applied in real life, along with best practices for implementing ML workflows.
AWS and other third-party sites provide sample questions and practice exams that emulate the actual certification test. Working through these will help you become familiar with the types of questions and the level of difficulty you can expect.
Case Studies
Go through AWS case studies as related to machine learning to understand how it is actually used in the field. That gives a good view on how AWS ML services are actually implemented in real-world work processes and provides insight that will be helpful not only during the exam, but even in real-world implementations.
Note: A pointed concentration on hands-on experience with AWS services, besides bringing in the best practices, will help someone prepare well to ace the AWS Machine Learning certification exam in one attempt.
Case Study: Real-World Example
The below section showcases a hypothetical case study to illustrate the ML workflow on AWS:
A healthcare organization aims to predict the readmission of patients by utilizing electronic health records (EHRs). The steps include the following:
Data Collection & Preparation
Collection of the required data from the EHR system of the organization and transmitting it to Amazon S3, the scalable storage solution of AWS. Examples of such data include but are not limited to: patient demographics, medical history, lab test results, and past admissions in the hospitals. Since healthcare-related data usually is incomplete or inconsistent, cleaning and preprocessing of such data should be performed by the organization.
This involves the handling of missing values, usually via imputation, and normalization of features, which may be in the form of scaling numeric data or encoding categorical variables. In essence, such preparation of data improves the quality and suitability of data to a large extent for training models.
Model Development and Training
With data prepared, the company then uses Amazon SageMaker as a powerful ML development tool to build and train the predictive model. Any variety of algorithms could be considered, such as either a random forest or GBMs to provide only two common examples; both methods are appropriate for classification problems.
ML with Amazon SageMaker now allows the healthcare team to try various models, tune hyperparameters, and assess various performance metrics, such as accuracy, precision, and recall. After all, this step will make sure the model fits well for the problematic prediction of patient readmissions using historical data.
Model Deployment
After the model has been trained and tuned, the deployment capability of SageMaker will be used, deploying the model as an endpoint. This step of deployment allows the model to be accessible for real-time predictions. The deployed model will be provided scalable infrastructure by SageMaker that would handle a load variety and provide results within a short time without explicitly managing any servers.
Model Serving
In any new admission, the healthcare team can send the data of the patient to the SageMaker endpoint, which will process the input data and predict the likelihood of readmission from the model. The predictions have the potential to inform clinical decisions, so enabling health care providers to focus on high-risk patients might allow them to adjust care plans with the possibility of preventing readmissions.
Model Monitoring
Continuous monitoring keeps the model valid and relevant over time. AWS services, such as Amazon CloudWatch and SageMaker Model Monitor, provide the organization with the ability to monitor real-time performance of the model.
If the model starts showing any signs of the beginning of concept drift-a situation where the relationship between the input data and the forecasted output changes-there are the alerts that trigger a retraining of the model. This keeps predictions reliable in the case of either a change in the patient population or healthcare practices.
Conclusion
Mastering ML Workflow on AWS is an important step in your career because it increases your prospects in cloud-based machine learning and optimization of AWS in providing scalability, automation and cost-effectiveness during deployment of models. By following this guide, you’ll have the essential information for real-world applications which is a core part of AWS machine learning specialty exams.
Hands-on experience is expected before taking the AWS Certified Machine Learning Specialty or AWS Certified Machine Learning Engineer Associate exam. Get hands-on directly with the no-risk AWS Sandbox boundary, free to use the AWS service to build, train, and then deploy different machine learning models.
- Tableau Data Analyst Salary and Job Trends 2025 - September 30, 2025
- Ultimate Java SE 21 1Z0-830 Preparation Guide for Beginners - September 30, 2025
- Best AWS Certification Courses in 2025 - August 22, 2025
- How to Pass the NVIDIA NCP-ADS Exam in 2025 - July 15, 2025
- Top 10 Topics to Master for the AI-900 Exam - July 10, 2025
- SC-401 Prep Guide: Become a Security Admin - June 28, 2025
- How Does AWS ML Associate Help Cloud Engineers Grow? - June 27, 2025
- Top 15 Must-Knows for AWS Solutions Architect Associate Exam - June 24, 2025
