

This blog discusses how AWS ready-made ML services can help you tame the ML labyrinth with its ability to process large and complex data quickly and focus more on your core competencies. The blog also focuses on AWS Certified Machine Learning Specialty certification, which equips developers like you with the skills to deploy and optimizing machine learning models on AWS and help organizations meet their business objectives. In addition, this certification provides a comprehensive understanding of ML principles and deployment techniques that you can use to harness the full ML potential.
Machine Learning Development Life Cycle (MLDC)
To streamline the development and deployment of ML models, development teams follow the Machine Learning Development Life Cycle (MLDC) – a structured, step-by-step iterative framework. The AWS Certified Machine Learning – Specialty closely aligns with MLDC, and it covers key aspects of each stage of the MLDC. With the knowledge you gather from this course, you will be able to apply MLDC in practice and decide the AWS services apt for each stage.
Machine Learning Development Life Cycle
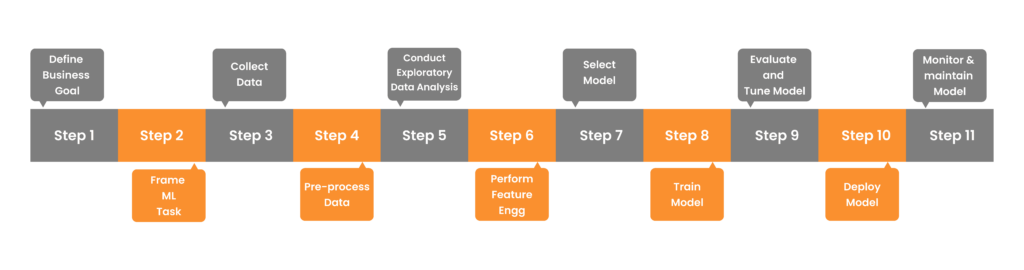
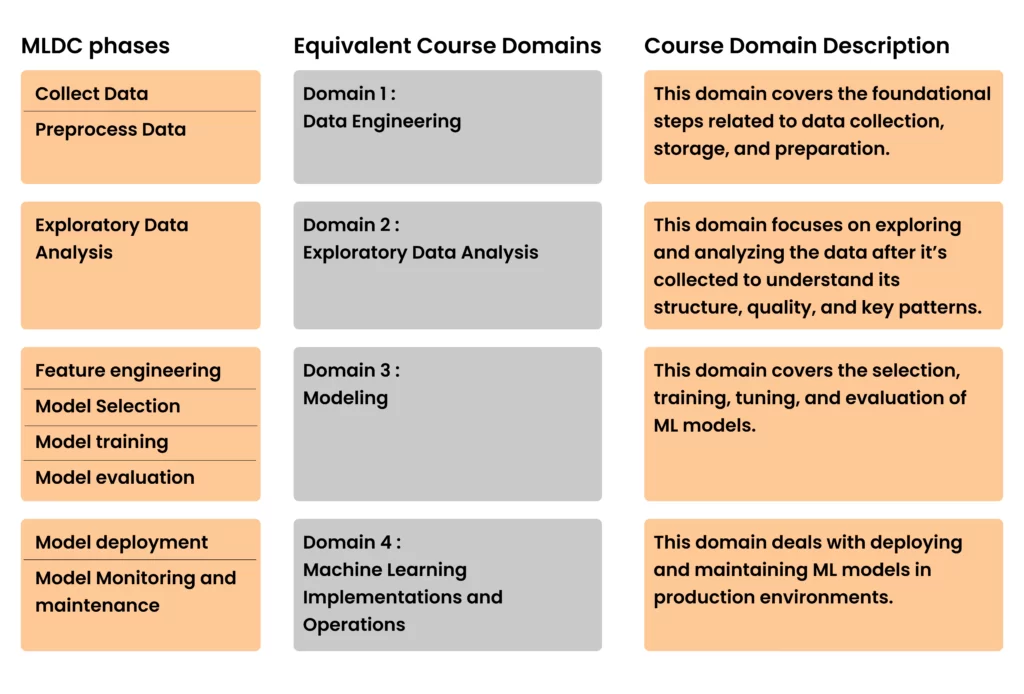
The four domains of AWS Certified Machine Learning Specialty exam cover the following phases in the MLDC. See CheetSheet for details.
Table 1. MLDC to Exam domain mapping
Define Business Goal and Frame ML Problem
Optimizing ML models starts with a clearly defined business goal, which in turn translates into a well-framed ML problem. The business goal is the overarching objective that the ML solution is designed to achieve, and it represents a real-world problem or opportunity the organization aims to achieve. Review your goal to determine if ML is the right solution. If yes, accordingly determine the ML model, data needed, the evaluation metric, and the deployment strategy.
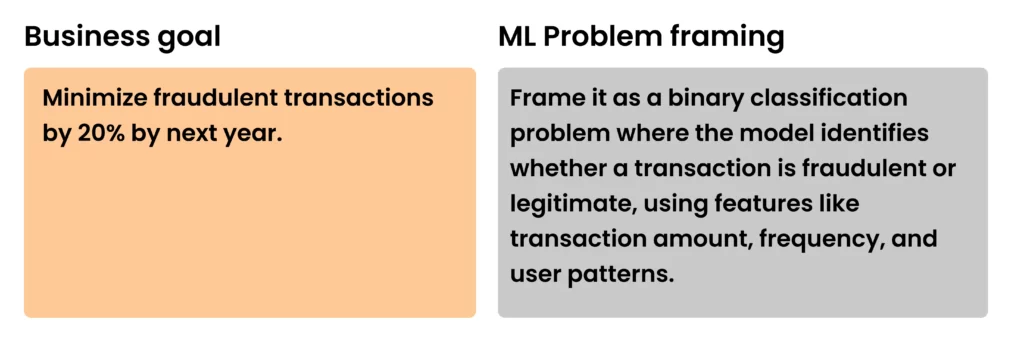
Problem framing describes the ML task that will help achieve the business goal. The problem defines the ideal outcome and the model’s goal, output, and success metrics. Here’s an example of a business goal and its ML problem.
Take the Whizlabs AWS Certified Machine Learning Specialty course to gain the expert knowledge required for identifying the business problem and identifying the appropriate ML approach.
Example – Business Goal and ML Problem Framing
Deploying and Optimizing Machine Learning Models on AWS
An optimized ML deployment ensures that models perform at their best while using resources efficiently and providing scalability and reliability in production environments. To ensure a model is optimized in production, you must consider several key factors. For example, data quality, deployment platform, model performance, deployment strategies, and others So, there is not a single approach to improving models. Hence, AWS offers a comprehensive suite of services, allowing you to select the right solution for a specific use case. The AWS Certified Machine Learning Specialty course will help you learn how to identify the appropriate AWS services to implement ML solutions.
In general, we can sum up model optimization in the following seven categories. Let’s review the AWS services that contribute to these categories.
- Data processing optimization
- Model Optimization
- Performance Optimization
- Deployment Optimization
- Security and Compliance Optimization
- Monitoring and Maintenance Optimization
- AI Optimization
Data Processing Optimization
An ML model is only as good as the data you feed it. Optimizing data processing is crucial for the performance and accuracy of the ML models. Data goes through several steps before it’s ready for ML consumption.
Data Collection and Ingestion:
- AWS Kinesis: capture and process streaming data in real-time. The three components of Kinesis are:
- Kinesis Data Streams: enable real-time data ingestion
- Kinesis Data Firehose: load data to AWS data stores
- Kinesis Data Analytics: perform real-time analytics
- Amazon Managed Streaming for Apache Kafka (Amazon MSK): use it for real-time data streaming, to maintain compatibility with your Kafka-based applications.
- AWS Glue: use it for batch processing of data lakes or data warehouses and for automated extract, load, and transform (ELT) operations.
Data Storage
- Amazon S3: store structured and unstructured data and use it as a data ingestion destination as it integrates seamlessly with other Amazon Web Services machine learning services.
- Amazon Redshift: store and analyze very large datasets in a petabyte-scale data warehouse that supports a relational database management system (RDBMS).
- Amazon DynamoDB: store non-relational (NoSQL) data with quicker real-time access, real-time inference, and low-latency response time.
- Amazon Elastic File System (Amazon EFS): use EFS as a common training data source for ML workloads and applications that run on multiple EC2 instances.
Data Transformation
- AWS Glue: automate data extraction, transformation, and loading and integrate data with a serverless approach
- Amazon Elastic MapReduce (Amazon EMR): transform large data sets in a distributed computing environment and get support for Hadoop Distributed File System (HDFC)
Data Query and Analysis
- Amazon Athena: query data stored in S3 using SQL without managing any servers.
Model Optimization
Amazon offers the AWS SageMaker platform—a low-code all-in-one umbrella of features and tools for building, training, and deploying machine-learning models:
- SageMaker pre-trained models and built-in algorithms: jumpstart your model building with ready-to-use built-in algorithms that support both supervised and unsupervised learning.
- SageMaker Studio: take advantage of a fully managed integrated development environment (IDE) that decouples code, compute, and storage.
- SageMaker Autopilot: leverages an AutoML solution that automatically creates a model from a given tabular dataset and target column name and displays it in a leaderboard.
- SageMaker Hyperparameter Tuning: automate the process of finding the best hyperparameter combination for your model.
Deployment Optimization
Deployment optimization ensures that your ML model is successfully deployed in the production environment. Here are some of the optimization services:
- AWS Lambda: runs serverless computing for deploying models without managing servers, which requires low-latency, on-demand inference.
- Amazon API Gateway: manage APIs for serving models, enabling scalable and secure access to ML predictions via RESTful APIs.
- AWS Fargate: run containerized ML models without managing server infrastructure.
- AWS IoT Greengrass: deploy ML models on edge devices such as IoT devices.
- AWS Step Functions: create an ML process as a series of steps that make up a workflow and let Step Functions orchestrate the workflows in order.
Performance Optimization
You can improve the efficiency and effectiveness of ML models using the right services and tools. Here are some of the optimization services:
- AWS Elastic Inference: accelerate inference for deep learning models by attaching GPU-powered inference acceleration to Amazon EC2 instances.
- AWS SageMaker Batch Transform: run batch inference on large datasets in the form of CSV or JSON files.
- AWS SageMaker Multi-Model Endpoints: deploy multiple models on a single endpoint, optimizing resource usage.
- SageMaker Endpoints: make real-time inference using REST API and enable auto-scaling to handle varying loads.
Security and Compliance Optimization
Security and compliance optimization ensures your ML environment is secure from threats and resulting financial losses, and compliant with fraud prevention regulations. Here are some of the optimization services:
- AWS Identity Access Management (AWS IAM): control access to ML resources using fine-grained access control, least privilege principle, role-based access control, and temporary security credentials. Use a single interface for managing access policies across all AWS services used in ML workflows
- AWS Key Management Service (AWS KMS): manage encryption keys to protect sensitive data in ML workflows. Encrypt training data, model artifacts, and logs in services such as Amazon S3, Amazon RDS, and AWS SageMaker.
- SageMaker security features: safeguard your ML environment from external threats by running training jobs and deploying models in an isolated network environment (Amazon Virtual Private Cloud – VPC). Integrate your model with CloudTrail and CloudWatch to detect unusual activities.
Monitoring and Maintenance Optimization
Monitoring and maintenance optimization will enable the ML model to run smoothly and effectively after it’s deployed. Here are the services you can use for optimization:
- AWS SageMaker Debugger: get insights during training to identify and resolve issues.
- Amazon CloudWatch: monitor models and receive logs metrics from models and infrastructure, showing performance and operational health.
- Amazon SageMaker Model Monitor: check monitoring reports on deployed models for data drift and performance degradation, with features to automatically retrain models if necessary.
- AWS CloudTrail: track API calls and user activities across AWS services to get visibility into resource usage and changes
AI Optimization
Amazon AI services add extra value to AWS ML deployments, providing advanced functionalities and ease of integration that complement the core ML capabilities. These AI services enhance the overall experience and effectiveness of deploying machine learning solutions on AWS.
- Amazon Comprehend: analyze and extract insights from the text; integrate large volumes of unstructured text data, such as customer feedback or social media posts into ML workflows for better decision-making.
- Amazon Transcribe: convert spoken language into written text and extract textual data from audio sources like customer service calls, interviews, or lectures, which can be used to train models.
- Amazon Lex: create chatbots and virtual assistants and automate customer interactions with real-time responses.
- Amazon Polly: convert text into lifelike speech in multiple languages and voices and enhance accessibility by providing spoken content for applications.
- Amazon Rekognition: identify objects, people, text, scenes, and activities in images and videos for advanced visual analysis and processing.
Use Case: Fraud Detection in International roaming
A telecom operator wants to deploy a real-time fraud detection system that monitors international roaming to safeguard against fraudulent activities and protect their revenue. The system will identify suspicious behavior patterns that deviate from normal user activities, such as unusually high call volumes or data usage in regions where the customer does not typically roam.
| Business Goal | Problem Framing |
| Minimize fraudulent international roaming by 20% by next year. | The problem is a binary classification task where the model must identify whether an international roaming transaction is fraudulent or legitimate. The features will include customer usage patterns, roaming locations, device information, and historical roaming activity. |
Figure. AWS Services for Optimizing the ML Deployment
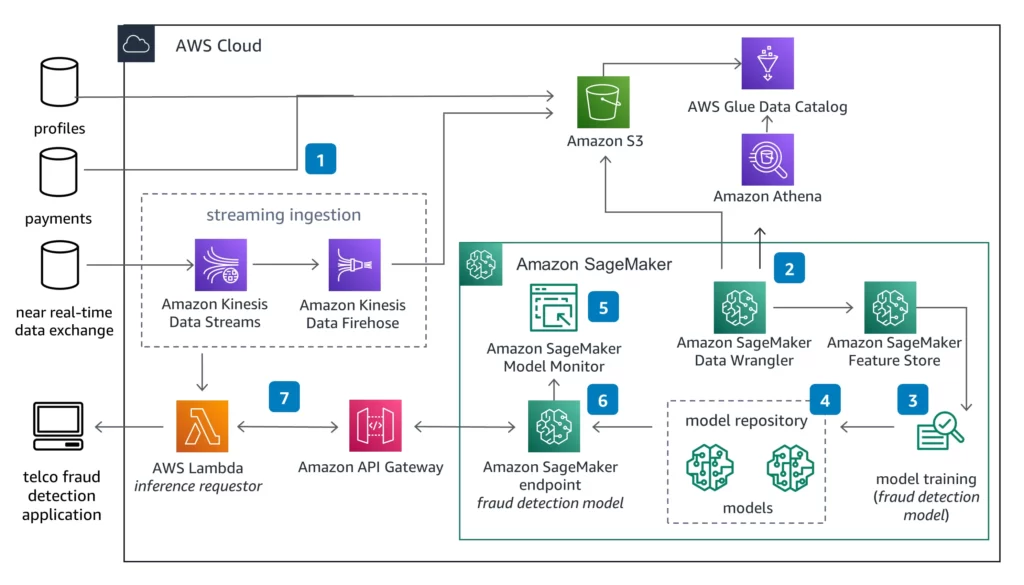
The preceding figure illustrates the different Amazon Web Services machine learning services used for optimizing model deployment:
Data optimization
- Telecom training data is batch transferred or streamed using Kinesis, into an S3 bucket. Glue (Data Catalog) stores the data.
- SageMaker (Data Wrangler) helps transform the data into features. Data is sourced directly from Amazon S3 or using Amazon Athena queries. Features are stored in Amazon SageMaker (Feature Store).
Model Optimization
- SageMaker trains the model for fraud detection and validates it for real-world use.
- Trained models are stored in SageMaker (Model Registry to track).
Deployment Optimization
- Amazon SageMaker Model Monitor monitors model quality over time, including data and model quality, and bias drift.
- SageMaker Endpoints provide near real-time inference and deploy the model.
- At inference time, data from the telecom operator and partners is streamed in using Kinesis to a Lambda function. API Gateway provides features to control access to the model endpoint.
The telecom operator consumes the fraud detection results the model produces.
Conclusion
AWS remains a popular choice for ML deployment for three main factors: scalability, security, and cost-effectiveness. By seamlessly integrating non-ML services with ML services, AWS facilitates a comprehensive solution and streamlined workflows. Such a cross-functional solution also needs a deployment team with a profound understanding of ML concepts and services to tap the boundless potential of model optimization. Earning the AWS Certified Machine Learning – Specialty (MLS-C01) is a testament to your ability to design, build, deploy, and maintain machine learning solutions. Sign up for Whizlabs AWS Certified Machine Learning Specialty course to earn this certificate. For additional hands-on experience of the services, check our AWS hands-on labs and AWS sandboxes.
- Mitigating DDoS Attacks on AWS with Security Specialty Certification Knowledge - October 17, 2024
- How to Connect AWS Lambda to Amazon Kinesis Data Stream? - October 3, 2024
- Deploying and Optimizing Machine Learning Models on AWS - September 3, 2024
- How to Pass Microsoft Azure Administrator Associate Exam on Your First Attempt - August 29, 2024