
If you’re aspiring to become a data integration specialist or enhance your skills in cloud-based ETL solutions, mastering Azure Data Factory is essential. Azure Data Factory is a powerful data integration service that allows you to create, schedule, and orchestrate data workflows across various data sources and destinations.
Pursuing the DP-203 certification can significantly boost your credibility and showcase your expertise in data engineering on Microsoft Azure.
However, cracking the Azure Data Factory interview can be challenging even for skilled professionals. Fear not!
In this blog, we’ll explore some commonly asked Azure Data Factory interview questions and answers to help you approach the interview process with confidence.
Let’s dive in!
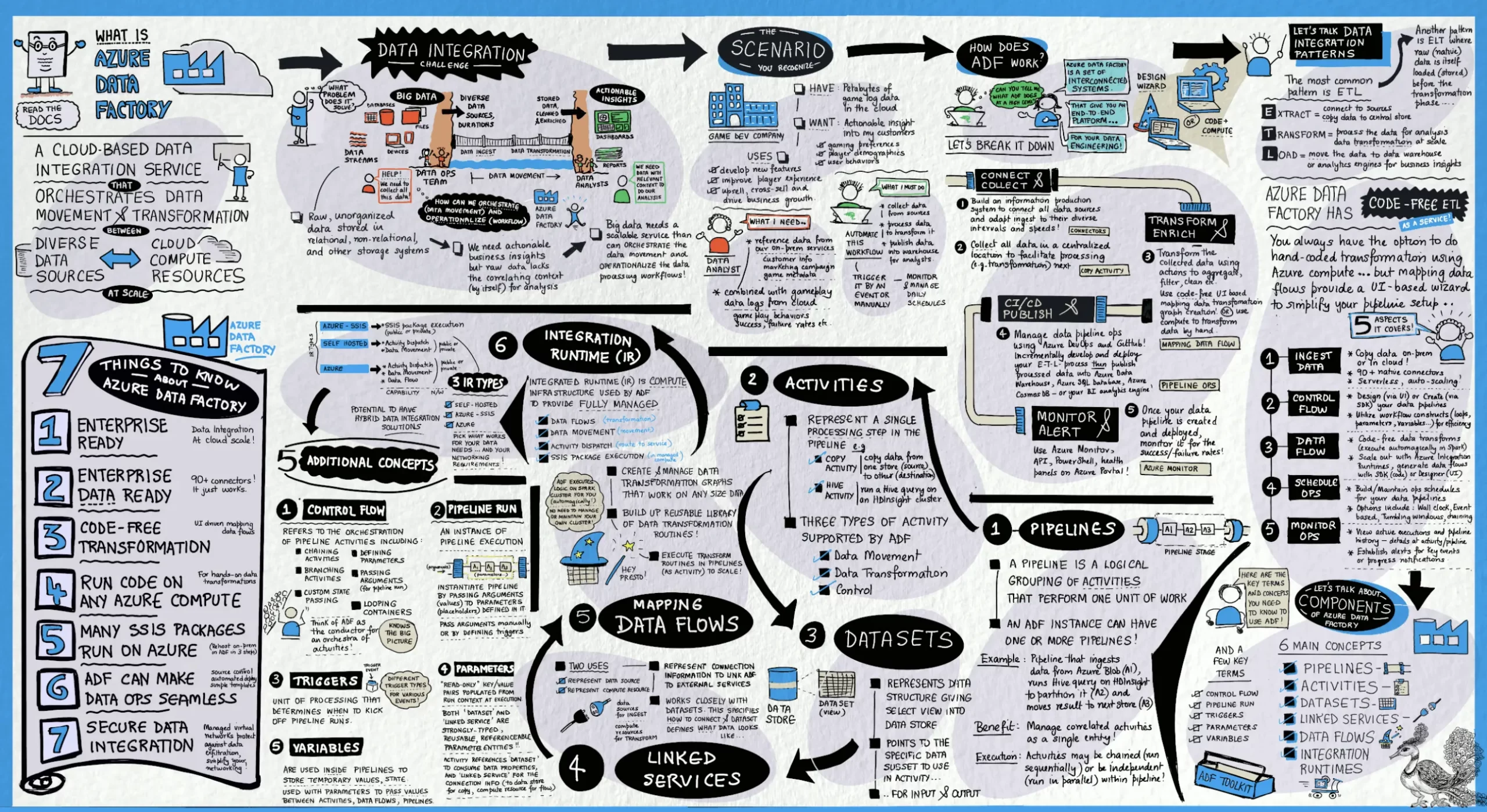
1. What is Azure Data Factory?
Azure Data Factory provides a solution for managing complex data scenarios. This cloud-based ETL (Extract, Transform, Load) and data integration service enables users to create data-driven workflows for orchestrating large-scale data movement and transformation tasks.
With Azure Data Factory, users can effortlessly design and schedule data-driven workflows, known as pipelines, to ingest data from various data sources. Additionally, users can construct intricate ETL processes to visually transform data using data flows, or leverage compute services like Azure HDInsight Hadoop, Azure Databricks, and Azure SQL Database.
Read More : What is Azure Data Factory?
2. What are the key components of Azure Data Factory?
The key components of Azure Data Factory include:
- Pipelines: Pipelines are the core building blocks of Azure Data Factory. They define the workflow for orchestrating data movement and transformation tasks. Pipelines consist of activities that represent individual tasks such as data ingestion, transformation, and loading.
- Activities: Activities are the units of work within pipelines. There are various types of activities, including data movement activities for copying data between different data stores, data transformation activities for processing and transforming data, control activities for branching and looping, and more.
- Datasets: Datasets represent the data structures and formats used by activities within pipelines. They define the schema and location of the data, including details such as file formats, paths, and connection information to the underlying data stores.
- Linked Services: Linked Services define the connection information and credentials required to connect to external data sources and destinations. They encapsulate the details of authentication, endpoint URLs, and other configuration settings needed to establish a connection.
- Triggers: Triggers are used to automatically execute pipelines on a predefined schedule or in response to events such as data arrival or system alerts. There are different types of triggers, including schedule triggers, tumbling window triggers, and event-based triggers.
- Integration Runtimes: Integration Runtimes provide the execution environment for activities within pipelines. They can be deployed in different environments such as Azure, on-premises, or in virtual networks to facilitate data movement and processing across diverse data sources and destinations.
- Data Flows: Data Flows provide a visual interface for designing and implementing data transformation logic within pipelines. They allow users to visually construct data transformation pipelines using a drag-and-drop interface, making it easier to build and manage complex ETL processes.
- Monitoring and Management Tools: Azure Data Factory provides built-in monitoring and management tools for tracking the execution of pipelines, monitoring data movement, and troubleshooting errors. Users can view pipeline execution logs, monitor performance metrics, and set up alerts for proactive monitoring and management.
3. When should you choose Azure Data Factory?
You should choose Azure Data Factory when you need a robust and scalable data integration service for orchestrating data workflows and performing ETL (Extract, Transform, Load) operations across various data sources and destinations. Specifically, Azure Data Factory is ideal for:
- Hybrid Data Integration: Integrating data from on-premises and cloud sources, supporting both structured and unstructured data.
- ETL and Data Transformation: Performing complex data transformations and moving data between different storage systems efficiently.
- Big Data Integration: Processing large volumes of data using Azure HDInsight, Azure Databricks, or Azure Synapse Analytics.
- Data Orchestration: Automating and scheduling workflows, ensuring reliable and repeatable data processing.
- Scalability and Flexibility: Leveraging its scalable architecture to handle increasing data volumes and diverse data processing requirements.
- Data Movement and Copying: Seamlessly moving data between various Azure services and external data sources.
- Cost-Effectiveness: Utilizing a pay-as-you-go pricing model, which can be more cost-effective compared to setting up and maintaining on-premises ETL solutions.
- Integration with Azure Ecosystem: Taking advantage of its seamless integration with other Azure services, such as Azure Storage, Azure SQL Database, and Azure Data Lake.
4. Is ADF an ETL or ELT tool?
Azure Data Factory (ADF) is both an ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) tool, depending on the specific use case and configuration.
ETL (Extract, Transform, Load)
In traditional ETL processes, data is first extracted from the source systems, then transformed according to the desired schema or structure, and finally loaded into the target destination. Azure Data Factory supports ETL workflows by providing capabilities for data extraction from various sources, transformation using data flows or compute services like Azure Databricks, and loading data into targeted places such as data warehouses or data lakes.
ELT (Extract, Load, Transform)
ELT processes involve extracting data from source systems, loading it directly into the target destination without significant transformation, and then performing transformations within the target environment. Azure Data Factory also supports ELT workflows by enabling users to ingest data from source systems and load it directly into target destinations. Users can then perform transformations on the loaded data using compute services like Azure SQL Database, Azure Databricks, or other data processing engines within the target environment.
5. How many activities are in Azure Data Factory?
Azure Data Factory provides a wide range of activities to support different data integration and transformation tasks. While the exact number of activities may vary over time as Microsoft continues to update and enhance the service, here are some common categories of activities available in Azure Data Factory.
- Data Movement Activities: These activities are used to copy data between different data stores, such as Azure Blob Storage, Azure SQL Database, Azure Data Lake Storage, on-premises SQL Server, and more. Examples include Copy Data, Azure Blob Storage, Azure SQL Database, and Data Lake Storage.
- Data Transformation Activities: These activities are used to process and transform data within pipelines. They include transformations such as mapping, filtering, aggregating, and joining data. Examples include Data Flow, Join, Filter, and Aggregate.
- Control Activities: Control activities are used to manage the flow of execution within pipelines. They include activities for branching, looping, conditional execution, and error handling. Examples include If Condition, For Each, Execute Pipeline, and Wait.
- Databricks Activities: These activities enable integration with Azure Databricks, allowing users to execute Databricks notebooks and run Spark jobs as part of their data workflows. Examples include Databricks Notebooks and Databricks Jar.
- Stored Procedure Activities: Stored Procedure activities are used to invoke stored procedures in relational databases such as Azure SQL Database or SQL Server. They allow users to execute custom logic and operations within the database environment.
- Web Activities: Web activities enable interaction with external web services and APIs as part of data workflows. They can be used to make HTTP requests, call REST APIs, or interact with web endpoints for data exchange.
- Custom Activities: Custom activities allow users to execute custom code or scripts within pipelines. They provide flexibility for integrating with external systems, performing specialized data processing tasks, or implementing custom business logic.
6. List some five types of data sources supported by Azure Data Factory.
Here are five types of data sources supported by Azure Data Factory:
- Relational databases (e.g., Azure SQL Database, SQL Server)
- Cloud storage services (e.g., Azure Blob Storage, Azure Data Lake Storage)
- On-premises data sources (e.g., SQL Server on-premises, file servers)
- SaaS applications (e.g., Salesforce, Dynamics 365)
- NoSQL databases (e.g., Azure Cosmos DB, MongoDB)
7. How many trigger types does Azure Data Factory support?
There are three types of triggers supported by Azure Data Factory.
- Schedule Triggers: These triggers execute pipelines on a predefined schedule, such as hourly, daily, or weekly intervals. They enable you to automate data integration workflows based on time-based schedules.
- Tumbling Window Triggers: Tumbling window triggers enable you to define recurring time intervals (e.g., every hour, day, week) during which pipelines are executed. They are useful for processing data in batches or windows of time.
- Event-Based Triggers: Event-based triggers execute pipelines in response to specific events, such as the arrival of new data, the completion of a data processing task, or an external trigger from another Azure service. They enable you to trigger data integration workflows dynamically based on real-time events.
8. Can Azure Data Factory process multiple pipelines?
Yes, Azure Data Factory can process multiple pipelines concurrently or sequentially, depending on your requirements and configuration. Here’s how Azure Data Factory supports processing multiple pipelines:
- Concurrent Execution: Azure Data Factory allows you to define and schedule multiple pipelines within a data factory instance. These pipelines can run concurrently, meaning that multiple pipelines can execute simultaneously, leveraging the available compute resources and maximizing throughput. Concurrent execution is beneficial for scenarios where you need to process multiple data workflows concurrently to meet SLAs or handle high-volume data processing tasks efficiently.
- Sequential Execution: Alternatively, you can configure pipelines to execute sequentially, where one pipeline starts only after the completion of the previous pipeline. Sequential execution ensures that dependencies between pipelines are honored, and data processing tasks are executed in a predefined order. Sequential execution is useful for scenarios where you have dependencies between data workflows or where you need to orchestrate complex data processing pipelines with dependencies or preconditions.
- Trigger-based Execution: Azure Data Factory supports various trigger types, including schedule triggers, tumbling window triggers, and event-based triggers. You can define triggers to automatically start and execute pipelines based on predefined schedules, time intervals, or external events. By configuring triggers for multiple pipelines, you can automate the execution of data workflows and ensure timely processing of data based on your business requirements.
- Monitoring and Management: Azure Data Factory provides built-in monitoring and management tools for tracking the execution of pipelines, monitoring performance metrics, and troubleshooting errors. You can monitor the execution status of individual pipelines, view execution logs, track performance metrics such as execution duration and data volumes processed, and set up alerts for proactive monitoring and management.
9. What is Datediff in Azure Data Factory?
In Azure Data Factory, DATEDIFF is a function used to calculate the difference between two dates or times and return the result in the specified date part (e.g., days, hours, minutes). The DATEDIFF function takes three arguments:
- Start Date: The date or time value representing the start of the time interval.
- End Date: The date or time value representing the end of the time interval.
- Date Part: The unit of time in which to return the difference between the two dates. This can be specified using predefined keywords such as “day,” “hour,” “minute,” “second,” etc.
The syntax for the DATEDIFF function in Azure Data Factory is as follows:
DATEDIFF(start_date, end_date, date_part)
10. How to set alerts in Azure Data Factory?
In Azure Data Factory, you can set alerts to monitor the health, performance, and status of your data integration pipelines and data factories. Alerts can notify you of critical issues, such as pipeline failures, high resource utilization, or data processing delays, enabling you to take timely action to address potential issues.
11. What is the distinction between Azure Data Lake and Azure Data Warehouse?
Azure Data Lake and Azure Data Warehouse are both cloud-based data storage and analytics services offered by Microsoft Azure, but they serve different purposes and are designed for different types of data workloads.
Here are the key distinctions between Azure Data Lake and Azure Data Warehouse:
| Azure Data Lake | Azure Data Warehouse | |
| Purpose | Store raw, unprocessed data of any type or format | Analyze structured, relational data using SQL-based tools |
| Data Structure | Supports structured, semi-structured, and unstructured data | Designed for structured, tabular data with defined schemas |
| Data Format | Supports various formats like JSON, CSV, Parquet, Avro, etc. | Requires data to be structured and loaded into tables |
| Processing and Analytics | Batch processing, real-time analytics, machine learning, etc. | SQL-based analytics, reporting, and business intelligence |
| Scalability | Offers limitless scalability for storing petabytes of data | Provides scalable compute and storage resources |
| Performance | Suitable for data science, exploratory analytics, and big data processing | Optimized for high-concurrency analytical queries and reporting |
| Cost Model | Pay-as-you-go pricing based on storage usage and data egress fees | Consumption-based pricing based on compute and storage usage |
12. What are the types of integration runtime?
There are three types of integration runtimes in Azure Data Factory:
- Azure Integration Runtime: This runtime is fully managed by Azure Data Factory and is used to perform data movement and transformation activities within the Azure cloud environment. It is optimized for transferring data between Azure services and can scale dynamically based on workload demands.
- Self-hosted Integration Runtime: This runtime is installed on your on-premises network or virtual machines (VMs) and enables Azure Data Factory to interact with on-premises data sources and destinations. It provides secure connectivity to on-premises systems without exposing them to the internet and supports data movement between on-premises and cloud environments.
- Azure-SSIS Integration Runtime: This runtime is used specifically for executing SQL Server Integration Services (SSIS) packages within Azure Data Factory. It allows you to lift and shift existing SSIS workloads to the cloud and provides native support for running SSIS packages in Azure with scalability and flexibility.
13. List out some useful constructs in Data Factory.
Here are some useful constructs in Azure Data Factory:
14. What is the purpose of Linked services
Linked services in Azure Data Factory serve as connections to external data sources and destinations. They provide the necessary connection information and credentials required for Azure Data Factory to interact with data sources and destinations during data integration and transformation tasks. The primary purpose of linked services is to enable Azure Data Factory to:
- Ingest Data: Linked services allow Azure Data Factory to extract data from various source systems, such as databases, files, APIs, and cloud services. By defining linked services for source systems, you can specify the connection details (e.g., server address, authentication method, credentials) needed to establish a connection and retrieve data from those sources.
- Transform Data: Linked services facilitate data transformation by providing connectivity to compute services and data processing engines. For example, you can define linked services for Azure Databricks, Azure HDInsight, Azure SQL Database, or Azure Synapse Analytics, allowing Azure Data Factory to invoke data transformation activities and execute data processing logic within these compute environments.
- Load Data: Linked services enable Azure Data Factory to load transformed data into target destinations, such as data warehouses, data lakes, databases, or cloud storage services. By defining linked services for target destinations, you can specify the connection details and authentication credentials required to write data to those destinations.
- Orchestrate Workflows: Linked services are essential for orchestrating end-to-end data workflows in Azure Data Factory. They provide the foundation for defining data pipelines, which consist of activities that interact with linked services to perform data integration and transformation tasks. By configuring linked services within pipeline activities, you can seamlessly move data between source systems, compute services, and target destinations as part of your data workflows.
15. What are ARM Templates in Azure Data Factory?
ARM (Azure Resource Manager) templates in Azure Data Factory are declarative JSON files that define the infrastructure and configuration of Azure Data Factory resources within an Azure environment. These templates follow the ARM template syntax and structure, allowing you to define and deploy Azure Data Factory resources in a consistent and repeatable manner using infrastructure as code (IaC) principles.
Explore hands-on practice for Understanding Azure Data Factory
Conclusion
I hope this blog post on “Top Azure Data Factory Interview Questions & Answers” has provided you with valuable insights and a solid understanding of the key concepts and practical aspects of working with Azure Data Factory.
Whether you are preparing for an interview or looking to enhance your knowledge, these questions and answers will help you confidently navigate the complexities of data integration and orchestration in Azure.
Best of luck with your interview and your journey in mastering Azure Data Factory!
- Study Guide DP-600 : Implementing Analytics Solutions Using Microsoft Fabric Certification Exam - June 14, 2024
- Top 15 Azure Data Factory Interview Questions & Answers - June 5, 2024
- Top Data Science Interview Questions and Answers (2024) - May 30, 2024
- What is a Kubernetes Cluster? - May 22, 2024
- Skyrocket Your IT Career with These Top Cloud Certifications - March 29, 2024
- What are the Roles and Responsibilities of an AWS Sysops Administrator? - March 28, 2024
- How to Create Azure Network Security Groups? - March 15, 2024
- What is the difference between Cloud Dataproc and Cloud Dataflow? - March 13, 2024