

In today’s data-driven world, businesses often face the challenge of efficiently managing and analyzing vast amounts of data from various sources. Extracting, transforming, and loading (ETL) this data into a consistent and usable format is crucial for successful data integration.
AWS Glue, a fully managed extract, transform, and load (ETL) service from Amazon Web Services (AWS), comes to the rescue by providing a seamless solution for data integration tasks.
It is better to take the AWS Certified Data Analytics – Specialty Certification to leverage AWS Glue’s capabilities.
This blog aims to walk through the topics like what is AWS Glue, its features, best practices, use cases, and its working. By going through this article, you can completely grasp the solid foundation of the AWS exam.
Let’s dig in!
What is AWS Glue?
AWS Glue is one of the AWS services and it is intended for analytical purposes. In general, AWS glue is termed a serverless data integration-based AWS service and it helps in analytical operations such as discovery, preparation, migration, and integration of data from varied sources. It also withholds productivity and data operations tooling options to monitor running jobs, authoring, and implementation of organization workflows.
With AWS Glue, the varied data sources and data management can be done in a centralized data catalog. And thus you are able to create, run, extract, transform, and load pipelines to upload the data into the data lakes. The data can be searched and queried from the cataloged data with the help of AWS services like Amazon Athena, Amazon EMR, and Amazon Redshift Spectrum.
Major data integration features are consolidated into a single service by AWS Glue. These consist of centralized cataloging, cleansing, modern ETL, and data discovery. Additionally, since it is serverless, there is no infrastructure to maintain. AWS Glue enables users across multiple workloads and types of users with adaptable assistance for all workloads including ETL, ELT, and streaming in a single service.
AWS Glue also makes it simple to integrate data throughout your architecture. It is integrated with Amazon S3 data lakes and AWS analytics services. From developers to business users, AWS Glue includes integration endpoints and job-authoring tools that are simple to use and offer solutions for a range of technical skill levels.
AWS Glue ETL The process of merging data from several sources into a sizable, central repository data warehouse is called extract, transform, and load (ETL). To organize and clean up raw data and get it ready for storage, analysis, and machine learning (ML), ETL utilizes a set of business rules.
Features of AWS Glue
The features that make up AWS Glue include:
- AWS Glue Data Catalog: You may catalog data assets and make them accessible across all AWS analytics services using the AWS Glue Data Catalog.
- AWS Glue crawler: Perform data discovery on data sources using AWS Glue crawler.
- Glue tasks on AWS: Employ either Python or Scala to carry out the ETL in the pipeline you have created. For ETL tasks, Python programs employ an extension of the PySpark Python dialect.
Through the usage of services like AWS Glue DataBrew and AWS Glue Studio, users can also interact with AWS Glue through a graphical user interface. By doing this, the service becomes more usable for complicated tasks like data processing which do not require highly developed technical abilities like code production or editing.
You only have to pay for the resources you really utilize with AWS Glue. There are no minimum fees. The service is one of many ETL tools provided by AWS, and it can be used in conjunction with other tools like Amazon EMR Serverless.
AWS Glue Working
The ETL (extract, transform, and load) jobs are orchestrated by AWS Glue using other AWS services to create output streams and construct data lakes and warehouses. To modify your data, produce runtime logs, save the task’s logic, and produce alerts to help you keep track of your task runs, AWS Glue uses API activities.
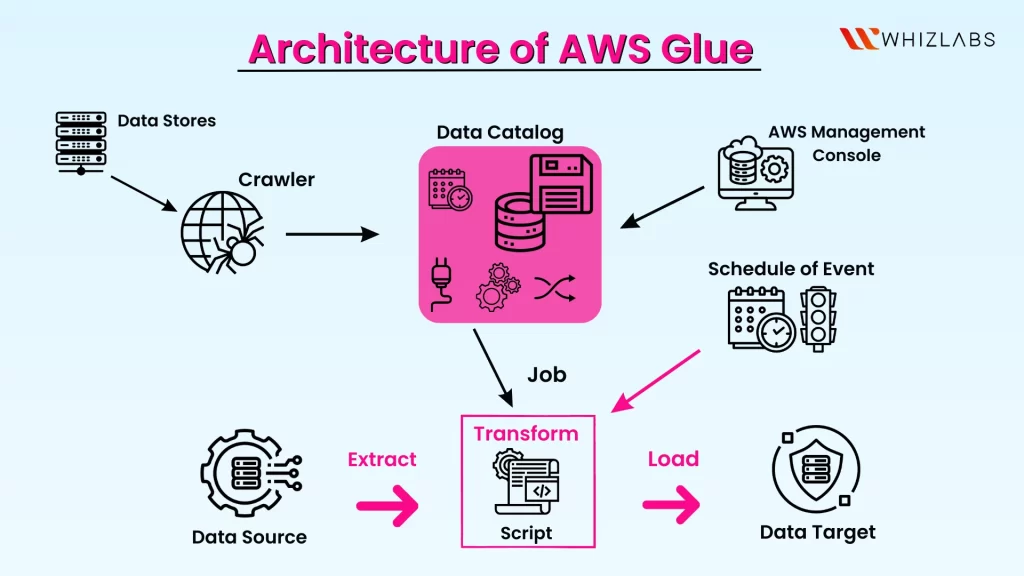
These services are linked together into an automated application by the AWS Glue dashboard, allowing you to concentrate on designing and overseeing your ETL operations. The console manages your administration and job development tasks. If you want to access the information from the data sources by the AWS Glue and publish it to data targets, it is essential to supply it with credentials and other attributes.
The resources needed to run the job are provisioned and managed by AWS Glue. AWS Glue runs the workload on an instance from a pool of resources when resources are needed to minimize startup time.
One can construct jobs using AWS Glue by using the table definitions in the Data Catalog. Jobs are made up of scripts that include the coding logic necessary to carry out the transformation. Triggers are used to start jobs either automatically or in response to a predetermined event. It is possible to choose which source data fills the target and where the target data is stored.
AWS Glue creates the necessary code to move the data from source to target based on the information you provide. To process your data, you can also include scripts through the AWS Glue console or API.
AWS Glue Use Cases
The following are the main data processing tasks that Glue carries out to arrange enterprise data:
- Extraction of data: Data is extracted by Glue in a range of formats.
- Transformation of data: Data is formatted for storage by glue.
- Integration of data: Enterprise data lakes or warehouses may include data with the usage of AWS Glue.
This is helpful for big data management companies who want to prevent data lake pollution, which occurs when an organization accumulates more data than it can use. Glue is specifically designed for companies that use serverless Apache Spark platforms to conduct ETL operations.
The following are some examples of popular use cases for Glue that are more detailed:
- To facilitate the management of the data integration process, Glue may integrate with the Snowflake data warehouse.
- Glue and AWS data lake are compatible.
- Athena and AWS Glue can work together for the schema creation.
AWS Glue Best practices
1. Using Partitions to Parallelize the Reading and Writing Operations
While processing the data by the AWS Glue, the partition process will be carried out. Partition involves dividing the data into parts and thus reading and writing operations will be done in a parallelized manner. It can better result in the reduction of cost and improved performance. While creating partitions, the data size, partition required and system load must be justified.
2. Improved Performance and Compression With the usage of Columnar File Formats
A sort of file format that is suited for column-oriented data repositories is called a columnar file format. These formats offer higher performance and compression, and that’s why they are frequently employed in data warehouses and analytics applications. Consider the amount of your data, the number of columns, and the available compression codecs when utilizing columnar file types with AWS Glue.
3. Optimization of data layout
Performance can be significantly impacted by data layout. When building a layout, the quantity of the data, the number of columns, the storage type, and various versions of the data should all be taken into account.
4. Usage of Interactive Sessions for Jupyter
For Jupyter notebooks and Jupyter-based IDEs, interactive sessions offer a highly scalable, serverless Spark backend, enabling effective interactive job creation with AWS Glue. It is simple and affordable to use interactive sessions because there are no clusters to deploy or manage, no inactive clusters to purchase, and no upfront configuration necessities.
You may dramatically increase the effectiveness of your AWS Glue development and reduce costs by using interactive sessions for Jupyter.
5. Improved AWS Glue Auto Scaling
In order to increase efficiency and speed while lowering costs, auto-scaling enables you to expand AWS Glue Spark jobs automatically depending on the dynamically estimated requirements during job runs. When working with enormous and erratic amounts of data on the cloud, this is particularly beneficial.
This eliminates the requirement for manual capacity planning ahead of time or data experimentation to figure out how much capacity is needed. Instead, you only need to indicate the maximum number of workers needed, and AWS Glue will dynamically assign resources depending on workload requirements while the task is running, adding new worker units to the cluster in almost real-time as Spark requires more executors.
6. Focusing on Incremental Change
When doing any alterations to the Amazon S3, the staged commits were used instead of going for large commits. Staged commits can permit to do the changes in small batches with the intention of failure reduction and rollbacks. This kind of approach can be largely helpful when you are just starting with AWS Glue.
AWS Glue pricing
In order to retain and access the metadata in the AWS Glue Data Catalog, AWS charges users a monthly fee. The per-second charge is also imposed with AWS Glue pricing, with either a minimum of 10 minutes or 1 minute as per the users working with AWS Glue, for the services like ETL job and crawler execution. And also charges will be imposed to get connected to a development endpoint for making interactive development.
FAQs
1. What type of tool is AWS Glue?
AWS Glue is a serverless service used for data integration that streamlines, accelerates, and reduces the cost of data preparation. In order to load information into the data lakes, it’s possible to graphically construct, run, and analyze ETL pipelines as well as identify and connect to over 70 different types of data sources. You can also manage the data in a centralized data catalog.
2. What are the limitations of AWS Glue?
Some of the drawbacks of using AWS Glue such as:
- Limited compatibility
- Learning curve
- Relational database queries
3. How is AWS Glue utilized in ETL?
Users may easily prepare and load their information for analytics with a fully managed ETL solution called AWS Glue. In just a few clicks, the AWS Management Console allows you to design and execute an ETL process.
Conclusion
Hope this article will equip you with the necessary knowledge to harness AWS Glue & how it works effectively.
By leveraging AWS Glue, businesses can streamline their data integration processes, accelerate data insights, and make data-driven decisions with ease. Whether it’s building data pipelines, creating data lakes, or performing complex data transformations, AWS Glue provides a comprehensive solution for organizations of all sizes.
AWS Glue empowers businesses to unlock the full potential of their data, enabling them to gain actionable insights and drive innovation in today’s data-driven landscape. If you want to become familiar with AWS Glue, try to utilize hands-on labs and sandboxes to use it in real-time settings.
If you have any queries on this blog post, please feel free to ping us now!
- Top 20 Questions To Prepare For Certified Kubernetes Administrator Exam - August 16, 2024
- 10 AWS Services to Master for the AWS Developer Associate Exam - August 14, 2024
- Exam Tips for AWS Machine Learning Specialty Certification - August 7, 2024
- Best 15+ AWS Developer Associate hands-on labs in 2024 - July 24, 2024
- Containers vs Virtual Machines: Differences You Should Know - June 24, 2024
- Databricks Launched World’s Most Capable Large Language Model (LLM) - April 26, 2024
- What are the storage options available in Microsoft Azure? - March 14, 2024
- User’s Guide to Getting Started with Google Kubernetes Engine - March 1, 2024